Nginx日志分析
最近登录服务又看到一大堆nginx的日志,一般每次看到我就less看一下也就删了。但这两天正好有空,
就想能不能用这些日志发现点什么有价值的信息。于是说干就干,马上打包日志下载到本地,然后操起大Python,
开始了一场数据分析之旅……
前言
最近把Jekyll搭建的博客翻新了一遍,主要是规范化了文章的永久连接(permlink)和分类标签。 好处是用起来更加规范,坏处就是在野的文章链接指过来的时候就404了。所以说重构最难的还是保持前向兼容, 不过还好我的访问量不高,可以不用顾忌太多甩开历史包袱。由于Jekyll都是是静态页面,所以对于很多访问的细节难以了解, 可以说在此之前我都是对其不管不顾的状态,也没太多时间维护。
由于全部是静态资源,所以一开始也部署了Nginx作为HTTP服务器。日志采用默认的格式产生,一直也没太关注, 这次正好藉着博客改版,尝试分析下近期的日志,以对网站状态有个全局的了解。
Nginx
Nginx是个开源的,高性能的HTTP服务器,反向HTTP代理服务器,以及IMAP/POP3代理服务器,功能强大,
因为我也只用过其部分子集,所以本文不对其做详细。这里要交待一下的是配置文件/etc/nginx/nginx.conf
的相关配置,因为后面会有相关:
user www-data;
pid /var/run/nginx.pid;
...
http {
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log error;
server {
listen 80;
server_name www.pppan.net;
location / {
root /path/to/jekyll/_site;
}
}
}可以看到这里没有指明日志的格式,因此采用默认设置,根据nginx-log-module 文档得知对于access_log,
其默认的格式是combined,如下所示:
log_format combined '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';对于错误日志error_log,一共有6个等级,分别是info, notice, warn, error, crit, alert(emerg),
默认的输出等级是error,所以上面配置里error_log xxx.log error中的error不写也是可以的。详情参考nginx core functionality。
总而言之,Nginx的日志分为访问日志access_log和错误日志error_log两大块,前者主要记录用户每次访问的情况,
后者则侧重于服务器的具体错误,比如返回403的具体原因是文件不可读还是权限不足之类的。
准备工作
现在有了日志,便可以着手开始处理了,但在此之前还是要先选择好工具。网上有许多日志分析采用的是简单粗暴的bash脚本(awk)来进行处理, 好处是分析速度快,但坏处是拓展性不强,如果未来想要做图表或者在网页前端展示就比较麻烦了。
因此我就挑了比较顺手的Python来做这个工作,因为其还能用matplotlib做些可视化的工作,看起来直观一点。
不过还是那句老话,语言只是工具,你也可以用php或者易语言,挑最顺手的来就行了。
访问日志
存储
从上面的配置文件可以看到我的访问日志保存在/var/log/nginx/access.log里,日志到了一定大小就会被压缩改名,
所以/var/log/nginx里的文件看起来是这样的:
用Python可以很容易将其全部提取出来合并,我将其取出然后存到数据库里,这样可以方便做些查询和聚合的操作,
这里为了简单起见因此选用sqlite3作为数据库,省去安装和配置MySQL的麻烦。表access的格式如下:
DROP TABLE IF EXISTS `access`;
CREATE TABLE `access` (
`ip` VARCHAR(64),
`user` VARCHAR(64),
`date` TIMESTAMP,
`request` VARCHAR(200),
`refer` VARCHAR(200),
`ua` VARCHAR(200),
`response_code` INTEGER,
`response_size` INTEGER);用Python读取每个文件每一行,并用正则表达式取出我们想要的内容,代码片段如下:
from dateutil.parser import parse
from dateutil import tz
TZ_LOCAL = tz.tzlocal()
pattern = re.compile(r'(?P<ip>.*) - (?P<user>.*) \[(?P<date>.*)\] "(?P<req>.*)" (?P<rcode>\d+) (?P<rsize>\d+) "(?P<ref>.*)" "(?P<ua>.*)".*')
for line in file:
match = pattern.match(line)
if match:
fmt_date = match.group('date').replace(':', ' ', 1)
foreign_date = parse(fmt_date)
local_date = foreign_date.astimezone(TZ_LOCAL)
cursor.execute("INSERT INTO `access` VALUES (?,?,?,?,?,?,?,?)",
(
match.group('ip'),
match.group('user'),
local_date,
match.group('req'),
match.group('ref'),
match.group('ua'),
match.group('rcode'),
match.group('rsize'),
)
)这里先将时间部分格式化成Python的dateutil可以读取的格式,然后由于我的服务器在美国且用的系统默认时区,
因此这里还将时区转换为本地时区。最后将记录插入到刚刚创建的数据库里。
分析
虽然日志清理了很多,只保留几个月的访问情况,但不妨碍我根据现有的字段,提取出一些我所关心的内容。 首先用下列命令分别获取总的访问数以及总的访问ip数:
SELECT COUNT(*) FROM `access`;
SELECT COUNT(DISTINCT `ip`) FROM `access`;结果一共有15325条访问记录,分别来自2101个不同的IP地址。
Top10
可以根据每个所关心的字段读取频率最高的前十看看是否有什么出乎意料的情况,这里以客户端IP,客户端User-Agent, 以及返回状态为例。
请求IP
首先获取访问频率最高的10个IP地址:
SELECT COUNT(*),`ip` FROM `access` GROUP BY `ip` ORDER BY COUNT(*) DESC LIMIT 10;获得数据后画成表格如下:
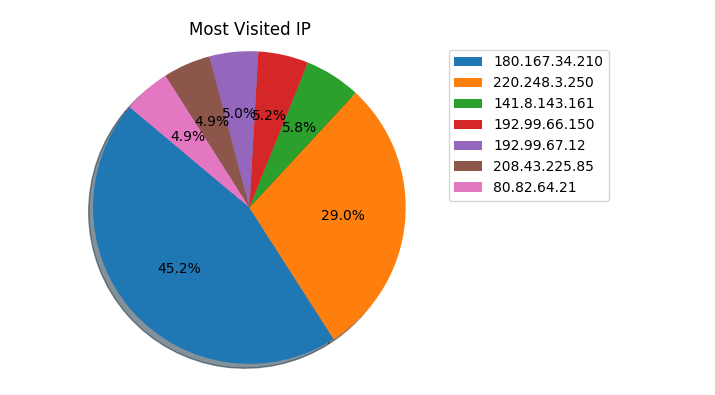
其中排名第一第二的都是我常用的出口IP,但不要被这个饼图误导了,因为前十加起来的访问量也不过三千左右, 占总量(15235)也才20%而已。事实上访问的IP来源是挺分散的,这里仅仅关注访问频率而已。可以看到除了我自己, 其他几乎都是爬虫,嗯,挺合理的。
User-Agent
获取访问频率最高的前10个User-Agent:
select COUNT(`ua`),`ua` FROM `access` GROUP BY `ua` ORDER BY COUNT(*) DESC LIMIT 10;结果如下:
2758|-
1465|Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
770|Mozilla/5.0 (Ubuntu; X11; Linux x86_64; rv:8.0) Gecko/20100101 Firefox/8.0
503|Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36; 360Spider
479|Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
302|Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0
290|Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0
286|Mozilla/5.0 (Linux; U; Android 5.0.2; zh-CN; Redmi Note 3 Build/LRX22G) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 OPR/11.2.3.102637 Mobile Safari/537.36
279|Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
257|Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
其中排名第一的是不带User-Agent的请求,紧随其后的是google的爬虫以及其他搜索引擎的爬虫,中间有几条来自浏览器的UA基本都是我自己乱入了。
状态码
HTTP请求的返回码也是一个值得关注的信息:
SELECT COUNT(*),`response_code` FROM `access` GROUP BY `response_code` ORDER BY COUNT(*) DESC;结果如下:
200|6676
301|3271
400|2487
502|1270
404|1147
304|435
206|15
499|10
403|8
504|6
除了200和301重定向以外,还有不少异常的请求,以502状态为例,随手拿几条出来看看:
149.202.98.160|-|2017-05-31 18:57:57+08:00|HEAD / HTTP/1.1|-|scan/0.01|502|0
91.230.47.3|-|2017-05-31 19:41:01+08:00|GET / HTTP/1.0|-|-|502|172
31.210.102.114|-|2017-05-31 19:52:39+08:00|GET / HTTP/1.0|-|masscan/1.0 (https://github.com/robertdavidgraham/masscan)|502|172
91.230.47.3|-|2017-05-31 20:45:07+08:00|GET / HTTP/1.0|-|-|502|172
91.247.38.53|-|2017-05-31 22:42:19+08:00|HEAD /categories.html HTTP/1.1|-|Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 OPR/42.0.2393.94|502|0
91.247.38.53|-|2017-05-31 22:42:28+08:00|GET /categories.html HTTP/1.1|-|Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.2) Gecko/20100316 AskTbSPC2/3.9.1.14019 Firefox/3.6.2|502|172
91.247.38.53|-|2017-05-31 22:42:31+08:00|GET /categories.html?geVG%3D8598%20AND%201%3D1%20UNION%20ALL%20SELECT%201%2CNULL%2C%27%3Cscript%3Ealert%28%22XSS%22%29%3C%2Fscript%3E%27%2Ctable_name%20FROM%20information_schema.tables%20WHERE%202%3E1--%2F%2A%2A%2F%3B%20EXEC%20xp_cmdshell%28%27cat%20..%2F..%2F..%2Fetc%2Fpasswd%27%29%23 HTTP/1.1|-|Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.2) Gecko/20100316 AskTbSPC2/3.9.1.14019 Firefox/3.6.2|502|172
可以看到大多数都是出于扫描器,估计是带了错误的HOST头导致Nginx无法正确代理,具体还要配合error_log查看。
上面的输出里最后一个请求有点奇怪,url decode如下:
/categories.html?geVG=8598 AND 1=1 UNION ALL SELECT 1,NULL,'<script>alert("XSS")</script>', table_name FROM information_schema.tables WHERE 2>1--/**/; EXEC xp_cmdshell('cat ../../../etc/passwd')#查了下IP是来自乌克兰,其实不算很惊讶,因为前面IP访问频率里排第三的就是来自俄罗斯的爬虫。这里根据最后三条记录来看,
应该是什么测试XSS和SQL注入的脚本,因为间隔比较短。不过能自动选择/categories.html这种可能带搜索的路径也是挺厉害的。
扯得有点远了,还是继续分析日志吧。
流量观察
对于一般网站来说流量监控也是比较重要的,所以根据访问时间,可以统计出每天的访问量和一天中平均各个时间段的访问量:
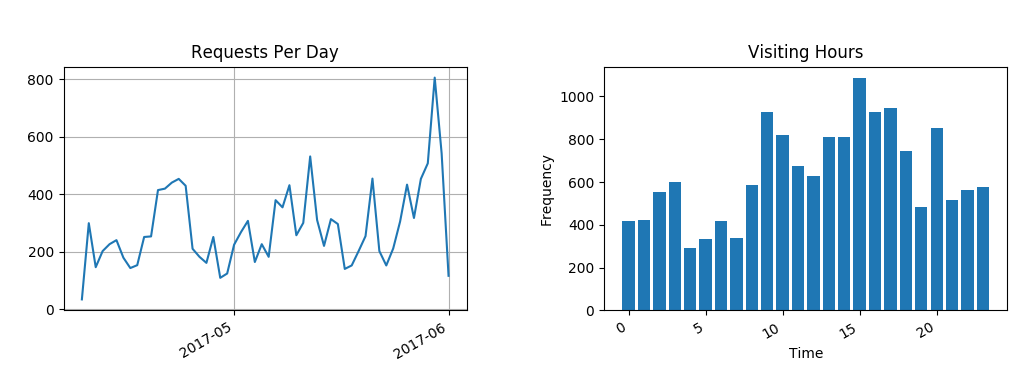
可惜这里只有几个月的访问日志,不过从左图能看到每天的访问量高低起伏很大,其中最高那里是5月31号端午节我在博客园发新博客的时候。 右图是24小时中各个时间段的访问频率,可以看到凌晨四点最低,下午三点最高,这里我都已经转换为北京时间了。
错误日志分析
错误日志也叫应用程序日志,主要用于方便开发者或者运维在出问题的时候排查原因。
存储
同样地,我们可以先把日志保存在数据库里:
DROP TABLE IF EXISTS `error`;
CREATE TABLE `error` (
`date` TIMESTAMP,
`level` VARCHAR(20),
`pid` VARCHAR(20),
`message` TEXT
);具体过程和访问日志的保存类似,就不再赘述了。
分析
错误日志相对于访问日志要少(废话),但从中也能找到对我们有价值的信息。
错误类型
首先看看都有哪些等级的错误:
select level,count(level) from error group by level;输出为:
error|2335 notice|9
很好,没有严重的错误,notice里的信息基本上就是Nginx重启的记录,error里则记录了许多异常的访问, 这也是要重点分析的。
路径错误
前一段时间改版了博客,因此导致文章路径和以前不兼容了
SELECT COUNT(*) FROM `error` WHERE `message` LIKE '%2: No such file or directory%';发现有1051个日志都是404错误,几乎占了所有错误日志的一半,下面是随便挑的一些日志详情:
4|connect() failed (111: Connection refused) while connecting to upstream, client: 109.169.29.30, server: bbs.pppan.net, request: "GET /robots.txt HTTP/1.1", upstream: "http://127.0.0.1:5000/robots.txt", host: "www.pppan.net"
3|open() "/home/pnz/html/pppan.net/_site/tech/2015/11/01/mitm-detail-1.html" failed (2: No such file or directory), client: 125.38.58.212, server: www.pppan.net, request: "GET /tech/2015/11/01/mitm-detail-1.html HTTP/1.1", host: "www.pppan.net", referrer: "http://www.cnblogs.com/pannengzhi/p/4989406.html"
3|open() "/home/pnz/html/pppan.net/_site/tech/p2p/2015/12/12/p2p-standard-protocol-stun.html" failed (2: No such file or directory), client: 121.35.211.124, server: www.pppan.net, request: "GET /tech/p2p/2015/12/12/p2p-standard-protocol-stun.html HTTP/1.1", host: "www.pppan.net", referrer: "http://www.cnblogs.com/pannengzhi/p/5048965.html"
3|open() "/home/pnz/html/pppan.net/_site/tech/2015/11/01/mitm-detail-1.html" failed (2: No such file or directory), client: 220.178.225.121, server: www.pppan.net, request: "GET /tech/2015/11/01/mitm-detail-1.html HTTP/1.1", host: "www.pppan.net"
2|open() "/home/pnz/html/pppan.net/_site/favicon.ico" failed (2: No such file or directory), client: 175.9.149.46, server: www.pppan.net, request: "GET /favicon.ico HTTP/1.1", host: "www.pppan.net"
2|open() "/home/pnz/html/pppan.net/_site/tech/2015/11/01/mitm-detail-1.html" failed (2: No such file or directory), client: 218.29.102.120, server: www.pppan.net, request: "GET /tech/2015/11/01/mitm-detail-1.html HTTP/1.1", host: "www.pppan.net", referrer: "http://www.cnblogs.com/pannengzhi/p/4989406.html"
2|open() "/home/pnz/html/pppan.net/_site/tech/p2p/2015/12/12/p2p-standard-protocol-stun.html" failed (2: No such file or directory), client: 123.157.208.18, server: www.pppan.net, request: "GET /tech/p2p/2015/12/12/p2p-standard-protocol-stun.html HTTP/1.1", host: "www.pppan.net", referrer: "http://www.cnblogs.com/pannengzhi/p/5048965.html"
可见"重构"这地雷是多么有破坏力啊。其中很多refer都来自博客园,所以我也赶紧把博客园里对应的文章连接都修改了一遍:(
SEO(搜索引擎优化)
我对SEO完全是门外汉,但即便是我也知道,如果每次搜索引擎的爬虫每次来你的网站都吃一鼻子灰,那你在搜索引擎里的结果肯定不怎么好看。 当然每个搜索引擎的优化策略也不尽相同,说起来和杀毒软件的查杀策略一样,需要有心人不断去摸索,去exploit。
鉴于google的爬虫访问我的频率最高,那我就尝试着对其友好一点。先在错误日志里找找有没有google相关的日志:
SELECT COUNT(*) FROM `error` WHERE `message` LIKE '%google%';
SELECT `message` FROM `error` WHERE `message` LIKE '%google%';说多也不多,说少也不少,一共有56条错误日志,其中大多数都是404错误,主要访问了以下内容:
GET /post_google_news.xmlGET /LocalNews.xmlGET /googlenews.xmlGET /googlesitemap.xmlGET /newssitemap.xmlGET /sitemap/news.xmlGET /tncms/sitemap/news.xml- …
这些东西我怎么会有嘛?!经过google得知这是sitemap即网站地图,爬虫根据地图可以更高效地遍历网站而省去许多无谓的跳转。
一般来说网站的sitemap存放于根目录/sitemap.xml,和/robots.txt一样,都是作用于爬虫。而上面的一些路径则主要针对google,
有的博客系统如wordpress,都提供了生成google news sitemap的插件,与RSS方式一样,Jekyll也可以很容易生成类似的XML,
只不过我现在志并不在此,所以就让它继续404吧~
查错示例
刚刚在分析access_log的时候发现一个乌克兰的IP(91.247.38.53)访问返回502错误网关的信息,但具体错误原因还不清楚,
通过对比error_log就能看出了:
SELECT * FROM `error` WHERE `message` LIKE '%91.247.38.53%';2017-05-31 10:42:19|error|14829#0|*6247 connect() failed (111: Connection refused) while connecting to upstream, client: 91.247.38.53, server: bbs.pppan.net, request: "HEAD /categories.html HTTP/1.1", upstream: "http://127.0.0.1:5000/categories.html", host: "23.95.112.93"
2017-05-31 10:42:28|error|14829#0|*6249 connect() failed (111: Connection refused) while connecting to upstream, client: 91.247.38.53, server: bbs.pppan.net, request: "GET /categories.html HTTP/1.1", upstream: "http://127.0.0.1:5000/categories.html", host: "23.95.112.93"
可见是访问了bbs.pppan.net这个我曾经开过的测试域名,当时用完忘记把DNS的A记录删掉了,而且nginx里对应的反向代理还开着,
所以就报了网关错误,和我当初预计的原因一样。
总结
通过分析一遍Nginx的日志,也学习了许多新知识,比如数据的可视化,搜索引擎的习惯以及一些XSS和SQL注入的方法等,
算是温故而知新吧。