深入了解GOT,PLT和动态链接

之前几篇介绍exploit的文章, 有提到return-to-plt的技术. 当时只简单介绍了
GOT和PLT表的基本作用和他们之间的关系, 所以今天就来详细分析下其具体的工作过程.
本文所用的依然是Linux x86 64位环境, 不过分析的ELF文件是32位的(-m32).
大局观
首先, 我们要知道, GOT和PLT只是一种重定向的实现方式. 所以为了理解他们的作用,
就要先知道什么是重定向, 以及我们为什么需要重定向.
重定向(relocations), 简单来说就是二进制文件中留下的"坑", 预留给外部变量或函数.
这里的变量和函数统称为符号(symbols). 在编译期我们通常只知道外部符号的类型
(变量类型和函数原型), 而不需要知道具体的值(变量值和函数实现). 而这些预留的"坑",
会在用到之前(链接期间或者运行期间)填上. 在链接期间填上主要通过工具链中的连接器,
比如GNU链接器ld; 在运行期间填上则通过动态连接器, 或者说解释器(interpreter)来实现.
比如:
$ file /bin/ls
/bin/ls: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked,
interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=3c233e12c466a83aa9b2094b07dbfaa5bd10eccd, stripped
可以看到/bin/ls的解释器是/lib64/ld-linux-x86-64.so.2.
在本文中, 用下面两个简单的c文件来进行说明, 首先是symbol.c, 定义了一个函数变量:
// symbol.c
int my_var = 42;
int my_func(int a, int b) {
return a + b;
}编译为动态链接库:
gcc -g -m32 -masm=intel -shared -fPIC symbol.c -o libsymbol.so
另一个文件是main.c, 调用该动态链接库:
// main.c
int var = 10;
extern int my_var;
extern int my_func(int, int);
int main() {
int a, b;
a = var;
b = my_var;
return my_func(a, b);
}分别编译两个版本, 位置相关的main和位置无关的main_pi, 具体会稍后解释.
# 位置相关
gcc -g -m32 -masm=intel -L. -lsymbol -no-pie -fno-pic main.c libsymbol.so -o main
# 位置无关
gcc -g -m32 -masm=intel -L. -lsymbol main.c libsymbol.so -o main_pi符号表
函数和变量作为符号被存在可执行文件中, 不同类型的符号又聚合在一起, 称为符号表.
有两种类型的符号表, 一种是常规的(.symtab和.strtab), 另一种是动态的(.dynsym和.dynstr),
他们都在对应的section中, 以main为例:
$ readelf -S ./main
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 5] .dynsym DYNSYM 080481ec 0001ec 0000b0 10 A 6 1 4
[ 6] .dynstr STRTAB 0804829c 00029c 000085 00 A 0 0 1
...
[33] .symtab SYMTAB 00000000 00120c 000490 10 34 52 4
[34] .strtab STRTAB 00000000 00169c 0001e1 00 0 0 1
常规的符号表通常只在调试时用到. 我们平时用的strip命令删除的就是该符号表;
而动态符号表则是程序执行时候真正会查找的目标.
位置无关代码
刚刚编译动态链接库时指定了-fPIC, 编译main_pi时(默认)指定了-pie, 其实都是为了
生成位置无关的代码, 那么什么是位置无关? 为什么要位置无关?
我们执行一个可执行文件的时候, 其实是先将磁盘上的该文件读取到内存中, 然后再执行. 而每个进程都有自己的虚拟内存空间, 以32位程序为例, 就有2^32=4GB的寻址空间, 从0x00000000 到0xffffffff. 这里暂时不深入介绍, 只需要知道虚拟内存最终会通过页表映射到物理内存中.
当然, 如果你感兴趣, 强烈推荐你去看下Gustavo Duarte的这篇文章.
按照链接器的约定, 32位程序会加载到0x08048000这个地址中(为什么?),
所以我们写程序时, 可以以这个地址为基础, 对变量进行绝对地址寻址. 以main为例:
$ readelf -S ./main | grep "\.data"
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[25] .data PROGBITS 0804a014 001014 00000c 00 WA 0 0 4
.data部分在可执行文件中的偏移量为0x1014, 加载到虚拟内存中的地址是0x0804a014.
其中 0x0804a014 - 0x08048000 (起始地址) = 0x2014, 再看main函数的汇编代码:
$ objdump -d ./main | grep "<main>" -A 15
080484db <main>:
80484db: 8d 4c 24 04 lea ecx,[esp+0x4]
80484df: 83 e4 f0 and esp,0xfffffff0
80484e2: ff 71 fc push DWORD PTR [ecx-0x4]
80484e5: 55 push ebp
80484e6: 89 e5 mov ebp,esp
80484e8: 51 push ecx
80484e9: 83 ec 14 sub esp,0x14
80484ec: a1 1c a0 04 08 mov eax,ds:0x804a01c
80484f1: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
80484f4: a1 20 a0 04 08 mov eax,ds:0x804a020
80484f9: 89 45 f0 mov DWORD PTR [ebp-0x10],eax
80484fc: 83 ec 08 sub esp,0x8
80484ff: ff 75 f0 push DWORD PTR [ebp-0x10]
8048502: ff 75 f4 push DWORD PTR [ebp-0xc]
8048505: e8 a6 fe ff ff call 80483b0 <my_func@plt>
注意 80484ec 这行, 可以看到获取变量直接用的绝对地址0x804a01c(正好在.data范围内).
用gdb(在启动程序之前)可看到该地址正是var变量的地址, 且初始值为10:
$ gdb ./main
(gdb) x/xw 0x804a01c
0x804a01c <var>: 0x0000000a
按绝对地址寻址, 对可执行文件来说不是什么大问题, 因为一个进程只有一个主函数.
可对于动态链接库而言就比较麻烦, 如果每个.so文件都要求加载到某个绝对地址,
那简直是个噩梦, 因为你无法保证不和别人的.so加载地址冲突. 所以就有了位置无关代码的概念.
以位置无关的方式编译的main_pi, 来看看其相关信息:
$ readelf -S ./main_pi | grep "\.data"
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[25] .data PROGBITS 00002014 001014 00000c 00 WA 0 0 4
偏移量还是固定的, 但Addr部分不再是绝对地址. 也就是说程序可以加载到虚拟内存的任意位置. 听起来很神奇? 其实实现很简单, 继续看看main()的汇编:
$ objdump -d main_pi | grep "<main>" -A 20
00000660 <main>:
660: 8d 4c 24 04 lea ecx,[esp+0x4]
664: 83 e4 f0 and esp,0xfffffff0
667: ff 71 fc push DWORD PTR [ecx-0x4]
66a: 55 push ebp
66b: 89 e5 mov ebp,esp
66d: 53 push ebx
66e: 51 push ecx
66f: 83 ec 10 sub esp,0x10
672: e8 36 00 00 00 call 6ad <__x86.get_pc_thunk.ax>
677: 05 89 19 00 00 add eax,0x1989
67c: 8b 90 1c 00 00 00 mov edx,DWORD PTR [eax+0x1c]
682: 89 55 f4 mov DWORD PTR [ebp-0xc],edx
685: 8b 90 f0 ff ff ff mov edx,DWORD PTR [eax-0x10]
68b: 8b 12 mov edx,DWORD PTR [edx]
68d: 89 55 f0 mov DWORD PTR [ebp-0x10],edx
690: 83 ec 08 sub esp,0x8
693: ff 75 f0 push DWORD PTR [ebp-0x10]
696: ff 75 f4 push DWORD PTR [ebp-0xc]
699: 89 c3 mov ebx,eax
69b: e8 20 fe ff ff call 4c0 <my_func@plt>
注意67c~682处, 和之前的区别是这次通过eax寄存器来对变量进行寻址, 不过有个__x86.get_pc_thunk.ax函数,
其作用很简单, 在之前的IOLI-crackme0x06-0x09 writeup中有简单介绍过:
objdump -d main_pi | grep "__x86.get_pc_thunk.ax" -A 2
000006ad <__x86.get_pc_thunk.ax>:
6ad: 8b 04 24 mov eax,DWORD PTR [esp]
6b0: c3 ret
作用就是把esp(即返回地址)的值保存在eax(PIC寄存器)中, 在接下来寻址用. 有人可能好奇, 为什么这么麻烦, 直接用eip寄存器不就行了? 其实64位下就是这样操作的! 不过32位下不支持直接访问PC寄存器, 所以就多了一层间接的函数调用.
扯远了, 经过672和677两条指令后, eax的值将等于相对当前PC指针的固定位移. 只看静态代码的话, 可知eax=0x677+0x1989=0x2000, 而这个地址是…
$ readelf -S ./main_pi | grep 2000 -C 1
[23] .got PROGBITS 00001fe4 000fe4 00001c 04 WA 0 0 4
[24] .got.plt PROGBITS 00002000 001000 000014 04 WA 0 0 4
[25] .data PROGBITS 00002014 001014 00000c 00 WA 0 0 4
.got.plt的起始地址! 这个section我们接下来会说到. 现在先看汇编的67c处, 通过eax+0x1c=0x201c获取了变量的值, 这个地址已经进入到了.data之中:
$ gdb ./main_pi
(gdb) x/xw 0x2000+0x1c
0x201c <var>: 0x0000000a
所以, 位置无关代码实际上就是通过运行时PC指针的值来找到代码所引用的 其他符号的位置, 不管二进制文件被加载到哪个位置, 都可以正确执行.
缺点
位置无关代码的缺点是, 在执行时要保留一个寄存器作为PIC寄存器, 有可能会导致寄存器不够用; 还有一个缺点是运行时要经过计算来获得 符号的地址, 从某种方面来说也对运行速度有点小影响.
优点
位置无关代码的优点就跟他名字一样, 可以保证加载到任意地址都能 正常执行, 这也是每个动态链接库都需要支持的.
动态链接
刚刚我们说位置无关代码的时候有看到, PIC寄存器为.got.plt的地址, 然后按偏移量
来获取变量. 上面只看了eax+0x1c即从.data段获取的内容(var), 还有一个参数是通过
eax-0x10即.got段之中获取的my_var. 后者是在symbol.c中定义的, 所以其内容在编译期
未知. 如果是静态链接, 则可以在链接时解析符号的值. 我们这里主要考虑动态链接的情况.
一些定义
上面说了很多.got, .plt啥的, 那么这些section到底是做什么用的呢. 其实这些都是 链接器(或解释器, 下面统称为链接器)在执行重定向时会用到的部分, 先来看他们的定义.
.got && .got.plt
我们常说的GOT, 即Global Offset Table, 全局偏移表, 包括了.got和.got.plt.
前者是全局变量,后者是全局函数。
.got.plt相当于.plt的GOT全局偏移表, 其内容有两种情况, 1)如果在之前查找过该符号, 内容为外部函数的具体地址. 2)如果没查找过, 则内容为跳转回.plt的代码, 并执行查找. 至于为什么要这么绕, 后面会说明具体原因.
这是链接器在执行链接时实际上要填充的部分, 保存了所有外部符号的地址信息. 不过值得注意的是, 在i386架构下, 除了每个函数占用一个GOT表项外,GOT表项还保留了 3个公共表项, 每项32位(4字节), 保存在前三个位置, 分别是:
其中, link_map数据结构的定义如下:
struct link_map
{
/* Shared library's load address. */
ElfW(Addr) l_addr;
/* Pointer to library's name in the string table. */
char *l_name;
/*
Dynamic section of the shared object.
Includes dynamic linking info etc.
Not interesting to us.
*/
ElfW(Dyn) *l_ld;
/* Pointer to previous and next link_map node. */
struct link_map *l_next, *l_prev;
};.plt
这也是我们常说的PLT, 即Procedure Linkage Table, 进程链接表. 这个表里包含了一些代码, 用来(1)调用链接器来解析某个外部函数的地址, 并填充到.got.plt中, 然后跳转到该函数; 或者 (2)直接在.got.plt中查找并跳转到对应外部函数(如果已经填充过).
.plt.got
说实话, 这部分我还不知道有什么具体作用, 可能是为了对称吧. 逃)
对于我们将要研究的main程序, 这些段的地址如下:
$ readelf -S main | egrep '.plt|.got'
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[12] .plt PROGBITS 080483a0 0003a0 000030 04 AX 0 0 16
[13] .plt.got PROGBITS 080483d0 0003d0 000008 00 AX 0 0 8
[23] .got PROGBITS 08049ffc 000ffc 000004 04 WA 0 0 4
[24] .got.plt PROGBITS 0804a000 001000 000014 04 WA 0 0 4
变量
有了上面的定义, 先看变量的解析过程, 以main为例(位置相关的), 查看需要重定向的符号:
$ readelf --relocs ./main
Relocation section '.rel.dyn' at offset 0x358 contains 2 entries:
Offset Info Type Sym.Value Sym. Name
08049ffc 00000206 R_386_GLOB_DAT 00000000 __gmon_start__
0804a020 00000605 R_386_COPY 0804a020 my_var
Relocation section '.rel.plt' at offset 0x368 contains 2 entries:
Offset Info Type Sym.Value Sym. Name
0804a00c 00000107 R_386_JUMP_SLOT 00000000 my_func
0804a010 00000307 R_386_JUMP_SLOT 00000000 __libc_start_main@GLIBC_2.0
my_var的地址为0804a020, 注意这里实际上是.bss段, 如下:
$ readelf -S main | grep 0804a020 -B 2
[24] .got.plt PROGBITS 0804a000 001000 000014 04 WA 0 0 4
[25] .data PROGBITS 0804a014 001014 00000c 00 WA 0 0 4
[26] .bss NOBITS 0804a020 001020 000008 00 WA 0 0 4
因为main.c里只是声明变量而且没初始化, 在链接前并不知道是否在外部定义. 同时, 该变量的值一开始是不知道的, 我们可以通过gdb来验证:
(gdb) x/dw 0x0804a020
0x804a020 <my_var>: 0
显示值为0, 但实际上在symbol.c中定义了其值为42, 启动前我们先在这里下个观察点, 看看究竟是什么时候加载进去的:
(gdb) set environment LD_LIBRARY_PATH=.
(gdb) watch -l *0x804a020
Hardware watchpoint 1: -location *0x804a020
(gdb) run
Starting program: /home/pan/project/cFile/shared_library/plt/main
Hardware watchpoint 1: -location *0x804a020
Old value = 0
New value = 42
0xf7ff2e08 in ?? () from /lib/ld-linux.so.2
(gdb) x/xd 0x804a020
0x804a020 <my_var>: 42
所以, 确实是链接器/lib/ld-linux.so.2负责填充了该变量的内容.
而且是在程序运行之前就完成了符号解析.
函数
接下来看看外部函数符号. 外部函数的内容(指令)也是像变量一样在 程序运行之前完成填充的吗? 其实这理论上是可以的, 事实上稍有不同.
静态分析
我们先从汇编看看main是如何调用my_func()函数的:
(gdb) disassemble main
Dump of assembler code for function main:
0x080484db <+0>: lea ecx,[esp+0x4]
0x080484df <+4>: and esp,0xfffffff0
0x080484e2 <+7>: push DWORD PTR [ecx-0x4]
0x080484e5 <+10>: push ebp
0x080484e6 <+11>: mov ebp,esp
0x080484e8 <+13>: push ecx
0x080484e9 <+14>: sub esp,0x14
0x080484ec <+17>: mov eax,ds:0x804a01c
0x080484f1 <+22>: mov DWORD PTR [ebp-0xc],eax
0x080484f4 <+25>: mov eax,ds:0x804a020
0x080484f9 <+30>: mov DWORD PTR [ebp-0x10],eax
0x080484fc <+33>: sub esp,0x8
0x080484ff <+36>: push DWORD PTR [ebp-0x10]
0x08048502 <+39>: push DWORD PTR [ebp-0xc]
0x08048505 <+42>: call 0x80483b0 <my_func@plt>
调用的地址是0x80483b0, 在.plt段中, 之前说了PLT的定义, 现在具体看看里面的内容:
(gdb) disassemble 0x80483b0
Dump of assembler code for function my_func@plt:
0x080483b0 <+0>: jmp DWORD PTR ds:0x804a00c
0x080483b6 <+6>: push 0x0
0x080483bb <+11>: jmp 0x80483a0
End of assembler dump.
首先是跳转到*0x804a00c, 该地址在.got.plt之中, 之前说了, .got.plt相当于
.plt的GOT, 而GOT本身相当于一个数组, 看看该"数组"的内容:
(gdb) x/4xw 0x804a00c
0x804a00c: 0x080483b6 0x080483c6 0x00000000 0x00000000
所以, 0x080483b0这里的跳转, 相当于跳转到0x080483b6, 即下一条指令! 这个多余的跳转先打个问号, 把流程走完再说. 接着, 跳转到了0x80483a0, 这个地址, 是.plt的起始地址, 这里的指令如下:
(gdb) x/2i 0x080483a0
0x80483a0: push DWORD PTR ds:0x804a004
0x80483a6: jmp DWORD PTR ds:0x804a008
跳转到了0x804a008, 在前面我们知道0x804a000是.got.plt的地址,
而在上一节的定义中, 也知道了.got表前三项的作用, 0x804a008
正好是第三项got2, 即_dl_runtime_resolve函数的地址. 0x804a004
则是调用该函数的参数, 且值为got1, 即本ELF的link_map的地址.
如下, 在进程未启动前, got1和got2都为0, 在启动时由链接器装填:
(gdb) x/4xw 0x804a000
0x804a000: 0x08049f0c 0x00000000 0x00000000 0x080483b6
因此, 实际上(第一次)调用my_func@plt就相当于调用了
_dl_runtime_resolve((link_map *)m, 0)! 其中link_map提供了运行时的必要信息,
而0则是my_func函数的偏移(在my_func@plt中push 0x0).
该函数定义在glibc/sysdeps/i386/dl-trampoline.S中, 关键代码如下:
_dl_runtime_resolve:
cfi_adjust_cfa_offset (8)
pushl %eax # Preserve registers otherwise clobbered.
cfi_adjust_cfa_offset (4)
pushl %ecx
cfi_adjust_cfa_offset (4)
pushl %edx
cfi_adjust_cfa_offset (4)
movl 16(%esp), %edx # Copy args pushed by PLT in register. Note
movl 12(%esp), %eax # that `fixup' takes its parameters in regs.
call _dl_fixup # Call resolver.
popl %edx # Get register content back.
cfi_adjust_cfa_offset (-4)
movl (%esp), %ecx
movl %eax, (%esp) # Store the function address.
movl 4(%esp), %eax
ret $12 # Jump to function address.从注释里也可以看出来, 该函数实际上做了两件事:
- 1)解析出
my_func的地址并将值填入.got.plt中. - 2)跳转执行真正的
my_func函数.
动态分析
上面虽然用了gdb, 但程序并未运行, 只是分析静态的汇编代码, 为了验证上面的说法,
我们需要进行动态分析. 接着上面的分析, 我们这次在调用_dl_runtime_resolve
前打上断点. 还记得之前在my_func@plt中一次多余的跳转吗? 当时打了个问号,
现在就来解答这个疑问. 在0x804a00c处打上观察点并运行:
(gdb) b *0x80483a6
(gdb) watch -l *0x804a00c
(gdb) run
Breakpoint 1, 0x080483a6 in ?? ()
(gdb) x/xw 0x804a00c
0x804a00c: 0x080483b6
(gdb) continue
Hardware watchpoint 1: -location *0x804a00c
Old value = 0x80483b6
New value = 0xf7fcf4f0
0xf7fe8113 in ?? () from /lib/ld-linux.so.2
(gdb) disassemble 0xf7fcf4f0
Dump of assembler code for function my_func:
...
可以看到, 在_dl_runtime_resolve之前, 0x804a00c地址的值为0x080483b6,
即下一条指令. 而运行之后, 该地址的值变为0xf7fcf4f0, 正是my_func的加载地址!
也就是说, my_func函数的地址是在第一次调用时, 才通过连接器动态解析并加载到
.got.plt中的. 而这个过程, 也称之为延时加载或者惰性加载.
延时加载
延时加载的好处是, 只有当外部函数被调用了才会去进行动态加载, 降低程序的启动时间. 而第一次加载之后, 对于后续的调用就可以直接跳转而不需要再去加载. 这样一方面减少了进程的启动开销, 另一方面也不会造成太多额外的运行时开销, 所以延时加载在当今也是广泛应用的一个思想. 对于位置无关的代码, 延时加载的过程也是类似的, 并没有太大区别. 读者可以自己去追踪一下.
相关攻击
上节的分析忽略了一个重要的地方, 那就是各个段的权限, 再重温一下各个section:
$ readelf -S main
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[12] .plt PROGBITS 080483a0 0003a0 000030 04 AX 0 0 16
[13] .plt.got PROGBITS 080483d0 0003d0 000008 00 AX 0 0 8
[14] .text PROGBITS 080483e0 0003e0 0001a2 00 AX 0 0 16
[23] .got PROGBITS 08049ffc 000ffc 000004 04 WA 0 0 4
[24] .got.plt PROGBITS 0804a000 001000 000014 04 WA 0 0 4
[25] .data PROGBITS 0804a014 001014 00000c 00 WA 0 0 4
[26] .bss NOBITS 0804a020 001020 000008 00 WA 0 0 4
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
为了使得结果更清晰, 我删除了一些无关的输出. 从上表的Flg行可以看到, 前三个段 都有可执行权限(X), 却没有写(W)权限; 而后几个都有写权限, 却不可执行. 现代的操作系统一般都支持NX特性, 所以这样的结果是很常见的.
同时, 这也是为什么要将PLT和GOT分开的原因. 链接器运行时填充的区域, 必须是可写的, 但可写的区域一般不可执行, 对外部变量没有影响, 但对于外部函数来说就需要 引入一个可执行的区域作为引导, 这就是PLT的作用.
ret2libc
我在栈溢出攻击和缓解中有提到, ret2libc的使用场景是当栈不可执行时,
直接跳转到libc.so某个函数的地址, 比如system(), 来获得shell.
不过前提是要知道libc.so在运行时的加载地址. 如果没启用ASLR, 这个地址是固定的.
启用ASLR之后就会有个随机的偏移, 如下:
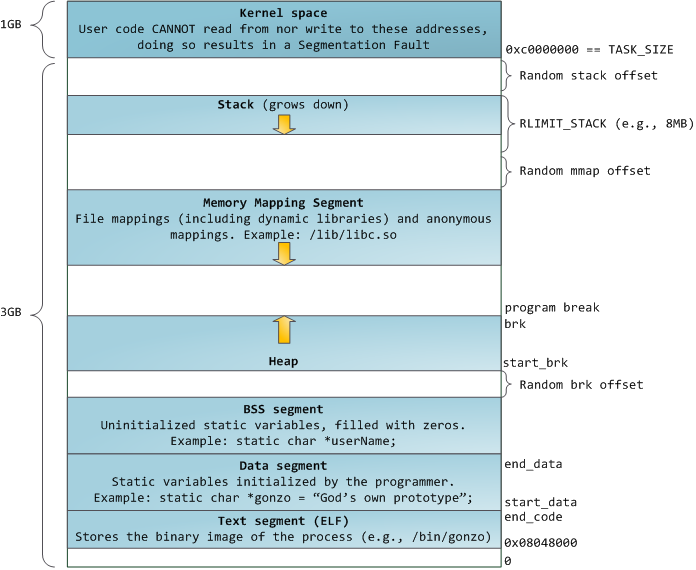
根据ASLR随机化的等级, 会在栈和内核空间之间, 栈和动态库(mmap)之间, 堆和.bss之间 都分别加上随机的偏移. 所以此时libc.so的地址是未知的, ret2libc攻击也就得到缓解了.
ret2plt
但是, 虽然ASLR随机化了上面的几个地址, 在位置相关代码的情况下, PLT的地址还是确定的! 所以如果没有启用位置无关代码的话, 即使启用了ASLR, 我们还是可以通过PLT来跳转到libc 中的函数执行, 这种攻击方法就叫ret2plt.
除此之外, 因为.got.plt是有写入权限的, 攻击者还可以通过代码中的内存破坏漏洞对 .got.plt段进行覆盖, 从而间接控制代码的执行流程.
攻击缓解
ret2plt这么屌, 就没人管管吗? 当然有! 一个最简单的办法就是启用位置无关代码,
不过就算可执行程序的代码是位置无关的, 链接器还是有可能将其加载到老地方.
一个更正确的缓解措施是RELRO即relocations read-only.
RELRO是链接器的一个选项, 可以通过man ld来查看. 主要作用就是令重定向只读.
有两个RELRO的等级, 部分RELRO和完全RELRO.
部分RELRO(由ld -z relro启用):
- 将.got段映射为只读(但.got.plt还是可以写)
- 重新排列各个段来减少全局变量溢出导致覆盖代码段的可能性.
完全RELRO(由ld -z relro -z now启用)
- 执行部分RELRO的所有操作.
- 让链接器在链接期间(执行程序之前)解析所有的符号, 然后去除.got的写权限.
- 将.got.plt合并到.got段中, 所以.got.plt将不复存在.
因此可以看到, 只有完全RELRO才能防止攻击者覆盖.got.plt, 因为在链接期间 就对程序符号进行了解析. 当然同时也放弃了延时绑定所带来的好处.
return-to-dlresolve
首先小结下本文的介绍:
.plt: 代码段(r-x),直接跳转到.got.plt中保存的地址,是plt的下一行或者绑定后的地址..got.plt: 数据段(rw-),保存了1,2,3以及plt的对应下一行地址,会在绑定后填充为实际地址..dynamic地址link_map地址 (启动后填充)dl_resolve地址 (启动后填充)
.got: 数据段(r–),与.plt类似,保存全局变量的引用位置。.plt.got: 数据段(r-x),与.plt类似,不过是保存外部变量的
其中.plt和.plt.got地址相邻,统称为PLT;.got与.got.plt地址相邻,统称为GOT。
为了方便对PLT/GOT的进一步理解,这里介绍下return-to-dlresolve技术。简单来说, 该利用技巧是利用dl_resolve的代码功能,去构造参数来解析需要的外部库(libc)函数。
原理
以puts函数为例,当前函数段如下:
0x8048154 - 0x8048167 .interp
0x8048168 - 0x8048188 .note.ABI-tag
0x8048188 - 0x80481ac .note.gnu.build-id
0x80481ac - 0x80481cc .gnu.hash
0x80481cc - 0x804822c .dynsym
0x804822c - 0x8048287 .dynstr
0x8048288 - 0x8048294 .gnu.version
0x8048294 - 0x80482b4 .gnu.version_r
0x80482b4 - 0x80482bc .rel.dyn
0x80482bc - 0x80482d4 .rel.plt
0x80482d4 - 0x80482f7 .init
0x8048300 - 0x8048340 .plt
0x8048340 - 0x8048348 .plt.got
0x8048350 - 0x8048532 .text
0x8048534 - 0x8048548 .fini
0x8048548 - 0x804855c .rodata
0x804855c - 0x8048590 .eh_frame_hdr
0x8048590 - 0x804867c .eh_frame
0x8049f08 - 0x8049f0c .init_array
0x8049f0c - 0x8049f10 .fini_array
0x8049f10 - 0x8049f14 .jcr
0x8049f14 - 0x8049ffc .dynamic
0x8049ffc - 0x804a000 .got
0x804a000 - 0x804a018 .got.plt
0x804a018 - 0x804a020 .data
0x804a020 - 0x804a024 .bss
其延时加载过程如下:
► 0x8048310 <puts@plt> jmp dword ptr [_GLOBAL_OFFSET_TABLE_+12] <0x804a00c>
0x8048316 <puts@plt+6> push 0
0x804831b <puts@plt+11> jmp 0x8048300
↓
0x8048300 push dword ptr [_GLOBAL_OFFSET_TABLE_+4] <0x804a004>
0x8048306 jmp dword ptr [0x804a008] <0xf7fee000>
↓
0xf7fee000 <_dl_runtime_resolve> push eax
0x8048300处的代码是所有plt共用的,负责传入link_map以及调用dl_resolve,称为PLT0。
在进入PLT0之前还push了一个参数,即index,这里是0。所以实际调用为:
dl_resolve(link_map, index)
在dl_resolve内部,会通过index来计算出所要解析的函数,并填写延时绑定的地址到指定位置。 我们想知道的问题有两个:
- dl_resolve如何通过参数知道要查找哪个函数
- dl_resolve将查找到的函数地址写到什么地方
接下来我们就带着问题去进行分析。
实现
显然,上面提到的两个问题,都是通过dl_resolve的参数去获取的,更准确的说,是通过index去获取的。 因为PLT0的代码是共用的,唯一有区别的是index的值。
dl_resolve的具体实现可以参考对应版本的libc源码,这里TLDR直接看伪代码:
Elf32_Rel *reloc = JMPREL + index
Elf32_Sym *sym = &SYMTAB[((reloc->r_info)>>8)]
// type 檢查,檢查是否為 R_386_JMP_SLOT
assert (((reloc->r_info)&0xff) == 0x7 )注意这里index是相对JMPREL的偏移,在x64中会有点区别,后面会说到。 其中JMPREL、SYMTAB、STRTAB是涉及到的dynamic section名称,如下:
$ readelf -d dummy
Dynamic section at offset 0xf14 contains 24 entries:
Tag Type Name/Value
0x00000001 (NEEDED) Shared library: [libc.so.6]
0x0000000c (INIT) 0x80482d4
0x0000000d (FINI) 0x8048534
0x00000019 (INIT_ARRAY) 0x8049f08
0x0000001b (INIT_ARRAYSZ) 4 (bytes)
0x0000001a (FINI_ARRAY) 0x8049f0c
0x0000001c (FINI_ARRAYSZ) 4 (bytes)
0x6ffffef5 (GNU_HASH) 0x80481ac
0x00000005 (STRTAB) 0x804822c <--
0x00000006 (SYMTAB) 0x80481cc <--
0x0000000a (STRSZ) 91 (bytes)
0x0000000b (SYMENT) 16 (bytes)
0x00000015 (DEBUG) 0x0
0x00000003 (PLTGOT) 0x804a000
0x00000002 (PLTRELSZ) 24 (bytes)
0x00000014 (PLTREL) REL
0x00000017 (JMPREL) 0x80482bc <--
0x00000011 (REL) 0x80482b4
0x00000012 (RELSZ) 8 (bytes)
0x00000013 (RELENT) 8 (bytes)
0x6ffffffe (VERNEED) 0x8048294
0x6fffffff (VERNEEDNUM) 1
0x6ffffff0 (VERSYM) 0x8048288
0x00000000 (NULL) 0x0
JMPREL (Elf32_Rel)
保存了一系列PLT reloc的地址,即.rel.plt段,reloc定义如下:
typedef uint32_t Elf32_Addr;
typedef uint32_t Elf32_Word;
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
} Elf32_Rel;
#define ELF32_R_SYM(val) ((val) >> 8) /* symbol index */
#define ELF32_R_TYPE(val) ((val) & 0xff) /* relocation type */- r_offset: .got.plt的位置,即延时绑定写回的位置(sym@got)
- r_info: symbol index + relocation type,见注释
JMPREL地址内容如下:
pwndbg> x/8xw 0x80482bc
0x80482bc: 0x0804a00c 0x00000107 0x0804a010 0x00000307
0x80482cc: 0x0804a014 0x00000407 0x08ec8353 0x0000a3e8
r_info中的0x07表示R_386_JMP_SLOT。
SYMTAB (Elf32_Sym)
一系列Symbol table的地址,即.dynsym段,结构体为Elf32_Sym:
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility under glibc>=2.2 */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;一个Elf32_Sym数据结构表示了一个符号的基本信息,如名称、地址、大小等。 例如:
STRTAB + sym->st_name中包含该符号名称字符串的地址- st_other: 符号是否可见
pwndbg> x/32xw 0x80481cc
0x80481cc: 0x00000000 0x00000000 0x00000000 0x00000000
0x80481dc: 0x0000001a 0x00000000 0x00000000 0x00000012
0x80481ec: 0x00000042 0x00000000 0x00000000 0x00000020
0x80481fc: 0x00000030 0x00000000 0x00000000 0x00000012
0x804820c: 0x0000001f 0x00000000 0x00000000 0x00000012
0x804821c: 0x0000000b 0x0804854c 0x00000004 0x00100011
0x804822c: 0x62696c00 0x6f732e63 0x5f00362e 0x735f4f49
0x804823c: 0x6e696474 0x6573755f 0x75700064 0x5f007374
||
\/
st_other
其实readelf重定向信息也是这样找出来的:
$ readelf -r dummy
Relocation section '.rel.plt' at offset 0x2bc contains 3 entries:
Offset Info Type Sym.Value Sym. Name
0804a00c 00000107 R_386_JUMP_SLOT 00000000 puts@GLIBC_2.0
.symtab是编译时的符号信息,这部分内容在strip时有可能会被删除。
STRTAB
包含了符号的名称:
name = STRTAB + sym->st_nameSTRTAB为字符串表的地址,即.dynstr段:
pwndbg> x/10s 0x804822c
0x804822c: ""
0x804822d: "libc.so.6"
0x8048237: "_IO_stdin_used"
0x8048246: "puts"
0x804824b: "__errno_location"
0x804825c: "__libc_start_main"
0x804826e: "__gmon_start__"
0x804827d: "GLIBC_2.0"
0x8048287: ""
0x8048288: ""
该名称用于实际在动态库中查找符号。
VERSYM
包含了重定向符号的版本:
uint16_t ndx = VERSYM[ (reloc->r_info) >> 8]
r_found_version *version = &l->l_version[ndx]ndx如果是0则使用local version.
示例
了解了几个TABLE的含义,我们再回顾下dl_resolve的实现:
Elf32_Rel *reloc = JMPREL + index
Elf32_Sym *sym = &SYMTAB[((reloc->r_info)>>8)]
// type 檢查,檢查是否為 R_386_JMP_SLOT
assert (((reloc->r_info)&0xff) == 0x7 )这是什么意思呢?Elf32_Rel中包含了重定向符号需要更新的地址r_offset,
以及符号详细信息的位置r_info,通过r_info可以在SYMTAB中定位到符号的
详细信息Elf32_Sym。Elf32_Sym在.dynsym段中,该段包括了运行时符号的描述,
如export/import的符号信息。
举例说明,还是看上面的puts函数,程序的对应段信息如下:
0x00000005 (STRTAB) 0x804822c
0x00000006 (SYMTAB) 0x80481cc
0x00000017 (JMPREL) 0x80482bc
puts的index为0,所以reloc = JMPREL+0= 0x80482bc,查看其内容:
p/x *(Elf32_Rel *)0x80482bc
$6 = {
r_offset = 0x804a00c,
r_info = 0x107
}
所以puts延时绑定后写入的位置应该是0x804a00c,即puts@got,
这个位置在.got.plt + 0xc处。也可以从plt的代码中看出来:
Dump of assembler code for function puts@plt:
=> 0x08048310 <+0>: jmp DWORD PTR ds:0x804a00c
0x08048316 <+6>: push 0x0
0x0804831b <+11>: jmp 0x8048300
根据r_info获取详细的符号信息Elf32_Sym *sym为:
&SYMTAB[((reloc->r_info)>>8)] = &SYMTAB[1] = 0x80481cc + sizeof(Elf32_Sym)
查看其内容:
pwndbg> p/x 0x80481cc + sizeof(Elf32_Sym)
$8 = 0x80481dc
pwndbg> p (Elf32_Sym *)0x80481dc
$9 = (Elf32_Sym *) 0x80481dc
p/d *(Elf32_Sym *) 0x80481dc
$10 = {
st_name = 26,
st_value = 0,
st_size = 0,
st_info = 18,
st_other = 0,
st_shndx = 0
}
由于st_name为26,所以计算出要解析的符号在STRTAB+26:
pwndbg> x/1s 0x804822c+26
0x8048246: "puts"
X64
64位ELF和32位的原理类似,不过处理方式和数据结构略有变化。
处理方式:
Elf64_Rel *reloc = JMPREL + index*3*8
Elf64_Sym *sym = &SYMTAB[((reloc->r_info)>>0x20)]
// = SYMTAB + (reloc->r_info)*3*8
// type 檢查,檢查是否為 R_X86_64_JMP_SLOT
assert (((reloc->r_info)&0xff) == 0x7 )前面说过在x86中,index是相对JMPREL的偏移,到了x64中变成了JMPREL数组的索引,
每个数组元素大小为RELAENT即sizeof Elf64_Rela即24字节。
一般而言x64中函数调用通过寄存器传递参数,但是dlresolve为了避免备份原始调用的参数寄存器, 而选择了使用自己的调用约定,即还是和x86一样通过栈来传递参数。
重定向信息:
typedef __u16 Elf64_Half;
typedef __u32 Elf64_Word;
typedef __u64 Elf64_Addr;
typedef __u64 Elf64_Xword;
typedef __s64 Elf64_Sxword;
typedef struct elf64_rela {
Elf64_Addr r_offset; /* Location at which to apply the action */
Elf64_Xword r_info; /* index and type of relocation */
Elf64_Sxword r_addend; /* Constant addend used to compute value */
} Elf64_Rela;
#define ELF64_R_SYM(i) ((i) >> 32)
#define ELF64_R_TYPE(i) ((i) & 0xffffffff)符号信息:
typedef struct elf64_sym {
Elf64_Word st_name; /* Symbol name, index in string tbl */
unsigned char st_info; /* Type and binding attributes */
unsigned char st_other; /* No defined meaning, 0 */
Elf64_Half st_shndx; /* Associated section index */
Elf64_Addr st_value; /* Value of the symbol */
Elf64_Xword st_size; /* Associated symbol size */
} Elf64_Sym;
我们通过设置index令结构体指向我们的地址,通常这个index都会偏大, 跨过text段指向data段,因此对于x64环境还有一点需要注意:
// dl-runtime.c
/* Look up the target symbol. If the normal lookup rules are not used don't look in the global scope. */
if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
{
const struct r_found_version *version = NULL;
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
{
const ElfW(Half) *vernum =
(const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}查找符号版本其实相当于:
uint16_t ndx = VERSYM[ (reloc->r_info) >> 0x20]
我们伪造sym就需要修改reloc->r_info中的symbol index,
这会导致在计算符号版本时VERSYM会超出取值范围,很可能造成段错误。
一个常见的解决方法是跳过这个分支的执行:
0x00007ffff7de9434 <+100>: mov rax,QWORD PTR [r10+0x1c8]
=> 0x00007ffff7de943b <+107>: test rax,rax
0x00007ffff7de943e <+110>: je 0x7ffff7de9530 <_dl_fixup+352>
0x00007ffff7de9444 <+116>: mov rax,QWORD PTR [rax+0x8]
0x00007ffff7de9448 <+120>: movzx eax,WORD PTR [rax+rdx*2]
0x00007ffff7de944c <+124>: and eax,0x7fff
即只需要令[r10 + 0x1c8]为0,此时r10的值为link_map的地址。
所以为了能在x64上利用,还需要向link_map + 0x1c8处写入0。
攻击思路
因此,要实现return-to-dlresolve攻击来调用未引用的外部函数,如system函数,
需要构造index参数,令其指向可控的地址,在其中构造Elf32_Rel对象,
使其r_info满足assert,以及r_offset指向构造的Elf32_Sym地址,
最后保证STRTAB + sym->st_name指向system字符串即可。
return-to-dlresolve的特点:
- 不需要leak memory就可以调用libc函数
- 必须可控制resolve参数,或者能改到
.dynamic - 需要在没有PIE和RELRO的情况下用。RELRO情况下link_map和dl_resolve都会填为0
注意事项
在构造Rel重定向对象以及Sym符号对象时,有几点需要注意:
reloc->r_info && 0xff == 7,这个assert检查是确保type为R_xxx_JMP_SLOT。reloc->r_offset指向的内存必须是可写的,因为要将查找结果写回改地址。- 最好令ndx即
VERSYM[ (reloc->r_info) >> 8]的值为0,不然可能找不到符号。 - 在x64情况下还需要注意VERSYM溢出的问题,一般通过将link_map + 0x1c8处置零解决。
总结
为了灵活利用虚拟内存空间, 所以编译器可以产生位置无关的代码. 可执行文件可以是位置无关的, 也可以是位置相关的, 动态链接库 绝大多数都是位置无关的. GOT表可写不可执行, PLT可执行不可写, 他们相互作用来实现函数符号的延时绑定. ASLR并不随机化PLT部分, 所以对ret2plt攻击没有直接影响. 为防止恶意修改got, 链接器提供了RELRO 选项, 去除got的写权限, 但也牺牲了延时绑定带来的好处.
另外本文也详细介绍了return-to-dlresolve攻击的原理,以加深延时绑定的理解。 在32位情况下可以无需信息泄露来主动解析和调用外部动态库;但在64位环境中, 仍需要泄露link_map地址来防止段错误。