ptmalloc与glibc堆漏洞利用
关于libc的堆管理和利用分析可以说是月经贴,在RSS或者论坛时不时就能看到一篇。对于这种情况,我只想说:这个月,该我了 :)
前言
大家都知道在Linux中,或者说glibc中,动态分配/释放内存使用的是malloc/free函数。那么malloc中获得的内存,是从哪来的呢?一个直观想法是可以通过系统调用直接转发给kmalloc,但这样效率太低。用户态的事,尽量在用户态解决。因此,另一个直观想法就是需要时申请一片空间,然后在用户态管理和分配这些空间。
堆分配器的目的和原理是大同小异的,各个不同的堆分配器区别主要体现在分配和管理策略上。
概念
先不看分配策略,malloc中的空间是从何而来的呢?了解的朋友应该都知道是通过brk/mmap系统调用实现。mmap如其名字所言,在进程的虚拟地址空间中创建新的地址映射;可以简单理解为直接向内核分配一定数量的页,POSIX兼容:
#include <sys/mman.h>
void *
mmap(void *addr, size_t len, int prot, int flags,
int fd, off_t offset);在实际的系统中,mmap一般支持多种类型的映射,比如支持直接将文件映射到内存中。
brk在应用层直接使用较少,但却历史悠久。在brk(2)中介绍,其主要作用是修改program break的位置。那么什么是program break呢?传统上一个进程在内存中会分成不同的片段(segments):
- 代码段(text/code segment):包含可执行的代码
- 数据段(data segment):包含编译器所知道的全局或者静态变量
- 栈(stack segment):包含一连串的栈空间
当然现在比以前更加复杂,包含只读数据段(.rodata)、未初始化的数据段(.bss)、mmap数据段、vdso段等。
按照传统的划分,进程动态申请更多内存的方法就是拓展数据段,并对拓展出来的空间进行管理。而program break,实际上就是数据段的末尾。
可以通过下面代码看brk的实际效果(sbrk返回新分配空间的指针):
int main() {
void *addr;
addr = sbrk(0);
addr = sbrk(1);
return 0;
}第一次返回0x56558000,对应的内存区域如下:
0x56557000 0x56558000 rw-p 1000 1000 /pwn/test_brk
第二次返回0x56558000,对应的内存区域如下:
0x56557000 0x56558000 rw-p 1000 1000 /pwn/test_brk
0x56558000 0x56559000 rw-p 1000 0 [heap]
可以看出sbrk是以页大小(0x1000)进行分配的,值得一提的是,第一次brk(0)调用之后所返回的地址,实际上就是.data段末尾的地址,这时候该地址还是没有映射的。如果两次brk中使用了printf,则结果则会大不相同。
总之,mmap和brk都是通过系统调用向内核申请新的映射(虚拟空间),brk在内核中可以认为是mmap对应未初始化数据匿名映射的简化实现。
dlmalloc
在介绍ptmalloc之前,我想先介绍下dlmalloc,因为ptmalloc很大程度上是基于dlmalloc的。
dlmalloc这名字其实是作者的名字——Doug Lea,这在早期算是一个很受欢迎的堆分配器,在保证内存碎片的情况下也兼顾了分配和释放的速度。我们重点关注dlmalloc算法的核心元素,而不会涉及具体的代码实现。
在dlmalloc和许多其他的堆分配器中,内存的分配和管理都是以块(chunk)为单位进行的,这样更容易进行组织。一个chunk就是一段大小固定的内存空间。
Boundary Tag
dlmalloc中一个重要的数据结构处理就是Boundary Tag,即边界标签。每个chunk都会在开头和结尾处包含额外标签,比如自身的大小和空闲信息。这样做有两个好处:
- 两个在地址空间中相邻的空闲chunk可以进行合并,变成一个大的chunk,从而减少内存碎片。
- 所有的chunk都可以通过任意一个已知chunk进行正向或者反向遍历找到。

当然,现代的实现中为了更加充分利用内存,去掉了使用中的chunk末尾的Tag。因为当chunk在使用中时,这些字段是用不到的。
Binning
bin可以理解为集装箱,chunk按照大小组织在同一个bin中进行管理(双链表)。最初版本的dlmalloc包含了128个大小固定的bin,每个bin的大小近似地按照对数进行增长。
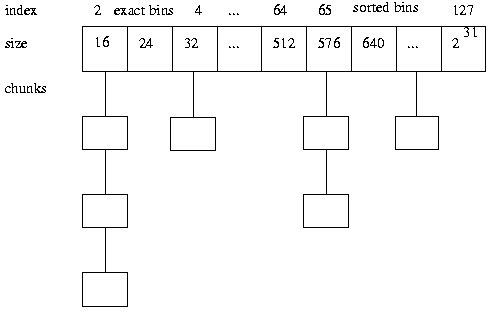
小于512的bin都只包含相同大小的chunk,寻找可用chunk采用的是best-fit策略。注意到前面说相邻的free chunk会进行合并,合并后的chunk会视情况放到下一个大bin中;而当分配时如果某个bin没有可用chunk,那么也是会从下一个bin中进行分裂,过程类似于Linux伙伴系统的分配策略。
大于512的bin使用的是另外一种分配策略(malloc_tree_chunk)。
除了这两大核心概念,dlmalloc的实现还考虑了局部性,临界chunk(brk/mmap)和缓存的优化,这里就不展开了。更多细节参考以下资料:
- A Memory Allocator – by Doug Lea
- Vudo - An object superstitiously believed to embody magical powers
- malloc.c
ptmalloc
ptmalloc从dlmalloc中fork而来,其名字(pthread-malloc)也预示着其对多线程的支持,在2006年集成到glibc中作为默认堆分配器实现。因此本文所讨论的ptmalloc,更准确地说是glibc中的ptmalloc,而不是最初的版本。
通常系统的堆内存是一段巨大的连续空间,ptmalloc将其分隔为多个不同的空间以优化多线程中的使用。每个这样的空间称之为arena。多个arena的存在可以让多个线程同时在多个arena中分配内存,从而提高运行效率。
值得一提的是,glibc中的malloc实现不需要保证chunk的大小为2的指数。不论每个chunk大小是多少,相邻的空闲chunk都能进行合并。这样进一步减少了内存碎片以及额外的内存开销。
以下的介绍中涉及的代码主要出自
glibc-2.27,因为这是ubuntu18.04的默认版本,操作系统默认为64位。所有其他版本可以从这里下载:
基本算法
ptmalloc的核心算法和dlmalloc类似,宏观地介绍如下:
- 对于较大的内存请求(≥512字节),这是个纯粹的best-fit分配器,通常符合FIFO先进先出的特性。
- 对于较小的内存请求(≤64字节),这是个缓存分配器,即从内存池中管理快速回收的chunk。
- 对于在这之间的内存请求,组合使用上述两个方法,尽量尝试同时满足两个目标。
- 对于巨大的内存请求(≥128KB),通常使用系统的mmap调用进行分配。
这就是算法的整体思路。对于多线程场景,主线程堆空间(main arena)同样是通过brk进行增长,而其他线程(per thread arena)则通过mmap进行分配。这也可以理解,因为brk只能增长program break,可内存在多个线程中是共享的,所以只有另寻他处。
数据结构
与dlmalloc核心元素类似,ptmalloc中有类似的chunk和bin的概念,实现中涉及到的数据结构主要有三个,下文分别介绍。
malloc_chunk
malloc_chunk结构表示内存中的一个chunk的头部(header),其定义如下:
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};不过就像注释所说比较容易让人误解,即误以为这些数据都是保存在每个chunk的头部的,实际上并非如此。
实际上这里也应用了dlmalloc中所提出的Boundary Tag技术,即在chunk头部和尾部包含size等信息(Tag),方便空闲chunk进行合并。由于free chunk本身是没有内容的,所以利用这个特点来将前一个chunk的Tag保存在free chunk的头部中,而当前free chunk的Tag则顺延,从而减少一个word大小。示例图如下:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
也就是说,free chunk和inuse chunk的头部内容并不相同。举例而言,如果前一个chunk空闲,那么mchunk_prev_size就是有意义的,否则只是包含了上一个chunk的用户数据;还有fd、bk指针对于inuse chunk来说也并不存在。
另外,对于Boundary Tag技术而言,这里Tag就是chunk_size本身,由于chunk的大小是8字节对齐的,因此最低log8=3位用不到,就腾出来记录额外信息,这3个bit从高到低分别是:
A:NON_MAIN_ARENA,也简写做N,表示chunk是否属于main arenaM:IS_MMAPPED,表示chunk所属空间是否为mmap而来P:PREV_INUSE,表示前一个chunk是否空闲
heap_info
一个heap指的是一片连续的内存空间,其中包含了许多(可聚结)的malloc_chunk,heap通过mmap进行分配并且起始地址总是HEAP_MAX_SIZE对齐的。heap_info结构描述的就是一个heap:
typedef struct _heap_info
{
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
size_t mprotect_size; /* Size in bytes that has been mprotected
PROT_READ|PROT_WRITE. */
/* Make sure the following data is properly aligned, particularly
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
MALLOC_ALIGNMENT. */
char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;每个thread arena中最初包含一个heap,当其内存用完后,会继续分配新的heap并加入到thread arena中。新分配的heap与之前的heap很可能不再是内存连续的了。
注:main arena使用brk拓展内存,只有一个heap,因此不存在heap_info。
malloc_state
上面说了一个arena可以包含一个或者多个heap,其中描述arena的数据结构就是malloc_state。
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
/* Flags (formerly in max_fast). */
int flags;
/* Set if the fastbin chunks contain recently inserted free blocks. */
/* Note this is a bool but not all targets support atomics on booleans. */
int have_fastchunks;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/* Linked list for free arenas. Access to this field is serialized
by free_list_lock in arena.c. */
struct malloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on
the free list. Access to this field is serialized by
free_list_lock in arena.c. */
INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};glibc不同版本有些许差异,但核心还是相近的,其中就包含了dlmalloc提到的bin。
main_arena的malloc_state是一个全局变量。
具体实现
Chunk
一个chunk的头部是malloc_chunk,根据其所处的位置和状态,大致有以下几种类型:
- Allocated Chunk
- Free Chunk
- Top Chunk
- Last Reminder Chunk
Allocated Chunk即已经返回给用户使用中的chunk,假设返回给用户的指针值是intprt_t mem,那么有mem = chunk + 8,此时chunk的大小即Boundary Tag保存在chunk + 4。
- prev_size:根据size的PREV_INUSED值,prev_size可能包含前一个free chunk的size信息也可能包含前一个allocated chunk的用户内容。
- size:当前chunk的tag,即size和A/M/P位信息。
Free Chunk是用户释放掉的chunk,此时fd和bk指针就有意义了,用来链接到对应bin的双链表中。
- prev_size:总是前一个allocated chunk的用户数据,因为任意两个相邻的free chunk会进行合并,因此前一个chunk肯定不是free chunk
- size:同
- fd:forward pointer,指向bin双链表的下一个chunk
- bk:backward pointer,指向双链表的上一个chunk
Top Chunk是最高的一个chunk,因为位于可用堆地址空间的末端,因此不保存在任何bin中。dlmalloc中将其大小设置为大于任何一个chunk,这样在所有bin都无法满足分配时,就从top chunk中获取;在top chunk的空间也不足的时候才通过系统调用去拓展空间。
Last Remainder Chunk在dlmalloc中是提高局部性分配的一种优化,其本身指向的是最近一次small request分配所分裂(所剩余)的空间。
Bin
ptmalloc继承了dlmalloc的Binning特性,不同类别的chunk集装在同一个bin中。在malloc_state中涉及到的bin如下:
...
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
...
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];每个bin本质上是一个元素为malloc_chunk指针的链表,这里用数组保存了所有的bin。
FastbinsY:包含所有fastbin的数组,其中的chunk称为fastchunk,fastchunk的最大size为80 * SIZE_SZ / 4,32位下是80字节,64位为160字节。
bins:包含了除fastbin以外的所有bin。与dlmalloc一样,小于512字节的bin包含的是同样大小的chunk,bin之间的大小为8字节递增。直接引用注释的说明如下:
64 bins of size 8
32 bins of size 64
16 bins of size 512
8 bins of size 4096
4 bins of size 32768
2 bins of size 262144
1 bin of size what's left
各个bin根据其作用不同,也被赋予了不同的名字,下面详细解释。
Fastbin
fastbin的作用是用来保存最近释放的small chunk。因此和其他bin不同的是fastbin为单链表而不是双链表,因为fastbin中的chunk不会从中间进行删除。同时,fastbin使用更快的LIFO处理顺序而不是其他bin中的FIFO。
保存到fastbin中的chunk的in_use位会被保留,也就是说fastchunk不会和相邻的chunk进行自动合并,但是fastbin可以释放所有chunk进行主动合并。
fastbin的数量和CPU位数有关,但本质都是从小到大递增8或16字节(SIZE_SZ * 2),直至其最大的大小80 * SIZE_SZ / 4。
Unsorted Bin
unsorted bin中保存的是所有其他chunk分裂生下来的chunk以及所有刚释放返回的chunk,不论大小。
这样处理的目的是给这些最近释放的chunk在被进入到对应bin之前一次重新被使用的机会。因此可以把unsorted bin看作是一个队列,进入其中的chunk要么被释放、合并,要么被取出继续使用或者放到其他bin中。
unsorted bin中的chunkNON_MAIN_ARENA 总是为0。
unsorted bin只有一个,即bin[1]。
Small Bin
smallbin中保存的是小于MIN_LARGE_SIZE的chunk,即small chunk。前面也说过,小于512字节的每个bin保存的都是相同大小的chunk,并且以8字节大小进行递增。
由于smallbin中chunk大小都是相同的,因此不需要进行排序。每个smallbin都是双链表,从头部加入,从尾部删除(返回给用户),遵循先进先出的顺序(FIFO)。
smallbin从bin[2]开始,共NSMALLBINS个。
Large Bin
largebin中保存的是大于等于MIN_LARGE_SIZE字节的chunk,与smallbin不一样的是,largebin中的chunk大小在同一个范围,但并不是完全相同的。largebin中的chunk需要按照size从大到小进行排序,所分配和释放的额外开销要大于smallbin。
largebin紧邻着smallbin,每个largebin大小范围根据bin的位置不同而不同,随着大小范围越大,bin的数量也就越少。
对于large chunk而言,在malloc_chunk中除了fd和bk指针,还包含了fd_nextsize和bk_nextsize指针,指向不同大小的chunk。
TCache
tcache(per-thread cache)在glibc2.26中引入,进一步提升堆管理性能。
/* We overlay this structure on the user-data portion of a chunk when
the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;tcache_entry用于链接空闲的chunk,指针直接指向chunk的userdata部分,也就是说复用了指针的含义。
每个线程都会维护一个tcache_prethread_struct,它是整个tcache机制的管理结构,其中包含TCACHE_MAX_BINS个tcache_entry链表。链入其中的chunk大小相同,所以通常也叫做tcache bin。其特性如下:
- 每个tcache bin最多只能有7个(
TCACHE_FILL_COUNT)chunk - tcache bin中chunk的inuse位不会置零,也就是说不会进行合并
- LIFO
可以看到其特性和fastbin是非常类似的。释放时在填满tcache之后才进入传统的释放过程,分配时也先从tcache中搜索。
tcache bin一共有64个(TCACHE_MAX_BINS),其大小范围为:
/* With rounding and alignment, the bins are...
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
idx 1 bytes 25..40 or 13..20
idx 2 bytes 41..56 or 21..28
etc. */由于tcache的增加和删除非常简洁,因此速度很快,但另一方面这也意味着缺乏各种安全检查和mitigation,在利用时候也格外方便。
分配与释放
在分析分配和释放的具体流程上,最好的方法其实是阅读源码(RTFSC),也有的人喜欢看一步步的文字解释。我这里按照自己阅读源码的过程将其简化为伪代码,或许可以更直观一些。
再次提醒,所分析的libc版本为2.27
_int_malloc
该函数代码近千行,梳理主要逻辑的伪代码如下:
void *_int_malloc(size) {
size_t nb = req2size(size);
chunkptr victim;
if (nb <= get_max_fast()) {
// 定位对应的fastbin,并在头部取出(FILO)
// 如果开启tcache,还会将bin中其他相同大小的chunk全部转移到tcache中
}
if (in_smallbin_range(size)) {
// 定位对应的smallbin,并在尾部取出,即bin->bk(FIFO)
// 如果开启tcache,还会将bin中其他相同大小的chunk全部转移到tcache中
} else {
// 请求为large request,因此需要先清理fastbin
malloc_consolidate(av);
}
// 在unsorted_bin中搜索
foreach(chunk : unsorted_bin) {
if (is_small && only_chunk && chunk_size > nb) {
// 分裂这个chunk,更新last_remainder并返回
}
if (chunk_size == nb) {
// 如果没开启tcache,直接返回
// 如果开启tcache,则先放到tcache,再次循环从tcache中取
}
// 只有一次机会,不是合适的chunk,直接释放到对应的bin中
if (in_smallbin_range(size)) {
// 放到对应的smallbin 头部
} else {
// 放到对应的largbin中,按照大小排序
}
if (in_tcache) return tcache_get();
}
if (!in_smallbin_range (nb)) {
// 在largebin中搜索,找到就返回
}
for (bin in bins) {
// 通过bitmap在smallbin中搜索,找到就返回
}
use_top:
// 都找不到合适的chunk,中top_chunk中分裂
// 如果不足以分离,通过sysalloc扩充top_chunk
}值得一提的是tcache的搜索在_int_malloc之前,优先级最高:
void *__libc_malloc(size) {
if (in_tcache) return tcache_get();
return _int_malloc(size);
}_int_free
释放逻辑的伪代码如下:
static void
_int_free (mstate av, mchunkptr p) {
size_t size = chunksize (p);
if (tcache) {
// 放到tcachebin中
}
if (size <= get_max_fast()) {
// 将chunk放到对应fastbin的头部
} else if (!chunk_is_mmapped(p)) {
if (!prev_inuse(p)) {
// 后向合并(backward)
p = prev_chunk(p);
unlink(av, p, bck, fwd);
}
if (nextchunk != av->top) {
if (!nextinuse) {
// 前向合并(forward)
unlink(av, nextchunk, bck, fwd);
size += nextsize;
}
// 将chunk放到unsorted bin中
} else {
// 将chunk与top_chunk合并,并成为新的top_chuck
av->top = p;
}
if (size > FASTBIN_CONSOLIDATION_THRESHOLD) {
// 如果释放的空间太大,就通过systrim回收给系统
malloc_consolidate(av);
systrim(heap);
}
} else {
munmap_chunk(p);
}
}free中这些操作大都是围绕两个目的:
- 减少内部碎片
- 加快下次分配的速度
记住这两点,那么其中的许多操作也就比较容易理解了。
另外由于篇幅原因,分析中省略了各种安全相关的assert,因为这和具体的libc版本有关,实际利用布局时需要根据具体的代码进行适配。
漏洞利用
漏洞利用的核心是在产生非预期的操作时,通过内存布局实现读写或者控制流劫持。堆漏洞利用也一样,我们的目标是通过小小的漏洞去构造出蝴蝶效应,在代码和数据的有序交互中开辟出一条新的道路。
glibc的漏洞利用已经有很多优秀的资料了,比如:
- heap-exploitation gitbook
- ctf-wiki/glibc-heap
- heap-exploitation by angleboy
- how2heap by shellphish
- Heap overflow using Malloc Maleficarum
- Extra Heap Exploitation by dangokyo
- …
因此我们主要介绍几个典型,而不深入各个House的细节之中。
unlink primitive
Binning是基于双链表而构造的,而在双链表中一个典型操作就是删除某个结点,也就是unlink操作。以fd和bk作为链表指针为例,unlink的实现一般是:
void unlink(chunk *c) {
FD = c->fd;
BK = c->bk;
FD->bk = BK;
BK->fd = FD;
}本质是让前后的结点绕过自己而进行连结。这个操作本身没有问题,但是却经常被攻击者滥用。
假设fd和bk的偏移分别为off_fd和off_bk,那么上述操作转换为内存读写是:
FD = *(c + fd_off);
BK = *(c + bk_off);
*(FD + bk_off) = BK; // 3
*(BK + fd_off) = FD; // 4
如果攻击者可以控制被unlink的chunk中的内容,即FD、BK的值是可控的话,那么就可以构造FD为目的地址x-bk_off,且BK为攻击者控制的地址y。则第3步就可以简化成:
*x = y;如果x是某个已知会被调用的函数指针地址,那就可以将其覆盖为BK,令BK指向我们的shellcode即可实现控制流劫持。当然这时候BK+fd_off处会被修改,实际构造shellcode可以跳过这几个字节。
其实除了ptmalloc,很多代码中只要有双向链表都会有类似的unlink操作,比如之前安卓内核中的的CVE-2019-2215,所以这类常见的pattern还是值得深入研究的。
单字节溢出
堆的单字节溢出在现实中通常更为常见。涉及到堆越界的基本上都和堆的数据结构(头部内容)强相关,所以这里着重讨论gblic的情况。
在可以溢出1字节的情况下,我们可以修改的区域为相邻的下一个chunk的size字段,因为prev_size实际上是在当前chunk的data部分的。溢出的思路有以下几种:
一、 拓展被释放块:当溢出的下一个chunk已经被释放并且存放在unsorted bin中时,通修改一字节将其扩大,这样下一次分配该chunk时后面的块就会被包含从而造成进一步溢出。
0x100 0x100 0x80
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 释放 B
|-------|-------|-------|
| A | B | C | 溢出 B 的 size 为 0x180
|-------|-------|-------|
| A | B | C | malloc(0x180-8)
|-------|-------|-------| C 块被覆盖
|<-- malloced-->|
二、拓展已分配块:当溢出块的下一块为使用中的块,则需要合理控制溢出的字节,使其被释放时的合并操作能够顺利进行,例如直接加上下一块的大小使其完全被覆盖。
下一次分配对应大小时,即可取得已经被扩大的块,并造成进一步溢出。
0x100 0x100 0x80
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 溢出 B 的 size 为 0x180 (C->prev_size)
|-------|-------|-------|
| A | B | C | 释放 B
|-------|-------|-------|
| A | B | C | malloc(0x180-8)
|-------|-------|-------| C 块被覆盖
|<-- malloced-->|
三、poison_null_byte:收缩被释放块,使其在之后分裂此块时将无法正确更新后一块的prev_size,导致释放时出现重叠的堆块。常用于null byte溢出中。
0x100 0x210 0x80
|-------|---------------|-------|
| A | B | C | 初始状态
|-------|---------------|-------|
| A | B | C | 释放 B
|-------|---------------|-------|
| A | B | C | 溢出 B 的 size 为 0x200
|-------|---------------|-------| 之后的 malloc 操作没有更新 C 的 prev_size
0x100 0x80
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | malloc(0x100-8), malloc(0x80-8)
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | 释放 B1
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | 释放 C,C 将与 B1 合并
|-------|------|-----|--|-------|
| A | B1 | B2 | | C | malloc(0x180-8)
|-------|------|-----|--|-------| 从B1开始,B2 将被覆盖
|<-malloced->|
通常B2是一个目标结构体,包含我们想要控制的有价值的指针。
四、 house_of_einherjar:同样是null byte溢出,不过覆盖后的下一个块prev_size可以找到前一个合法的块,并与其进行合并。
0x100 0x100 0x101
|-------|-------|-------|
| A | B | C | 初始状态
|-------|-------|-------|
| A | B | C | 释放 A
|-------|-------|-------|
| A | B | C | 溢出 B,覆盖 C 块的 size 为 0x200,并使其 prev_size 为 0x200
|-------|-------|-------|
| A | B | C | 释放 C
|-------|-------|-------|
| A | B | C | C 将与 A 合并
|-------|-------|-------| B 块被重叠
|<----- malloced ------>|
其他技巧
如果是针对时间紧张的CTF场景,还是要对常见版本的libc利用烂熟于心,比如how2heap命名的那些。当然要想熟悉利用技巧,对于malloc和free的代码实现也需要不断加深理解。
- house_of_spirit:构造一个fake chunk并进行free,加入到fastbin之后令下一次分配相同的大小返回我们的fake chunk(LIFO)。这种方法的关键点是需要配置好fd指针以及下一个chunk的size以满足各种检查。
- house_of_force:溢出到top_chunk,修改其size,从而令所有超大的分配都能从top_chunk返回而不通过mmap;然后通过malloc(&top-x)大小的分配返回任意地址。
- house_of_lore:
(< 2.26),利用smallbin和largebin在头部插入尾部取出的特性(FIFO),伪造bin中某个chunk的bk指针,这样在chunk出链之后下一个分配的就是我们的fake chunk。 - house_of_orange:
(< 2.26),类似force,不过是将top chunk的size改小,从而令分配时拓展top chunk,旧的top chunk进入unsorted bin。 - house_of_einherjar:
(< 2.26),Hiroki Matsukuma提出的单字节溢出的利用技巧,溢出修改前面相邻chunk的size和prev_in_use位,令其在释放时与我们的chunk进行合并,从而令malloc返回任意地址。 - house_of_botcake:绕过tcache double free的技巧。
- house_of_rabiit:构造fastbin fake chunk,并通过触发malloc consolidate来令其成为合法的chunk。
- house_of_roman:RCE through Leakless HeapFengShui, fastbin alloc anywhere.
- …
No more house, plz.
后记
漏洞利用的本质是内存布局,而内存布局的本质是通过可控的异常去修改程序本身有限状态机的逻辑,从而达到任意读写/控制流劫持等目的。为此,我们在脑海中就要对所exploit的目标运行流程有清晰的认识,不能有丝毫不确定性,0就是0,1就是1。即便在多任务高并发的场景中,比如内核,其涉及的不确定性本身也是确定的。成功的攻击除了统顾全局,对细节的把握也至关重要。