ptmalloc cheatsheet
最近公司被要求参加某网络安全比赛,所以借此机会又重新阅读了 glibc malloc 的最新代码,发现了许多之前未曾深究的细节。故整理成此文,也算是对从前文章的补充了。
前言
几年前已经写过了一篇 ptmalloc 与 glibc 堆漏洞利用,但是一来当时学习仓促,很多内容自己也只是一知半解;二来已经时过境迁,当时的 glibc 距今也更新了不少,而且当时理解的内容太久没有复习又全部还给老师了。因此,本文又重新将其整理一遍,当然不再介绍基础概念,只记录重点以备考试时快速查阅。
数据结构
首先在 arena 中实际上只分成两个 BIN,分别是 fastbinsY 和 bins。而 bins 中包含了常用的 unsorted bin、small bin、large bin,统称为 regular bins。
在 regular bins 数组中,bin_at(0) 不存在,bin_at(1) 为 unsorted bin,小于 MIN_LARGE_SIZE 的为 small bin,大于等于则为 large bin。对于 32/64 位系统来说,该值分别为 0x200/0x400:
#define NBINS 128
#define NSMALLBINS 64
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT // -> 0x08/0x10
#define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ) // -> 0
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH) // -> 0x200/0x400
双链表 Trick
上面说到 unsorted bin 对应 bin_at(1),但注意不要与 bins[1] 弄混,其实现如下:
#define unsorted_chunks(M) (bin_at (M, 1))
#define bin_at(m, i) \
(mbinptr) (((char *) &((m)->bins[((i) - 1) * 2])) \
- offsetof (struct malloc_chunk, fd))可以看到 bin_at 对应的 bins 索引是 (i-1) * 2,而且取到地址之后还回退一个偏移。乍看起来很奇怪,但实际上这是写代码的一个小优化,返回的地址会转换为 chunk 指针,但实际上并不是一个正常的块,而只是将其当做一个空闲的头部,只使用其中的 fd/bk 字段,分别指向不同的 bin。假设返回的指针是 P,则有:
P->fd = m->bins[(i-1) * 2];
P->bk = m->bins[((i-1) * 2) + 1];
也就是说,bin_at(i) 返回的 chunk, 似 chunk 又非 chunk,本身在 bins 中占两个坑,虽然不能当做真的 chunk 返回给用户使用,但是却正好当做双链表的固定表头。
实际测试一下可能更清楚一些,在 unsorted bin 为空时,有以下属性:
pwndbg> p *main_arena.bins[0]
$1 = {
mchunk_prev_size = 94692393318320,
mchunk_size = 0,
fd = 0x7f5bfe942cc0 <main_arena+96>,
bk = 0x7f5bfe942cc0 <main_arena+96>,
fd_nextsize = 0x7f5bfe942cd0 <main_arena+112>,
bk_nextsize = 0x7f5bfe942cd0 <main_arena+112>
}
pwndbg> distance main_arena.bins[0] &main_arena.bins[0]
0x7f5bfe942cc0->0x7f5bfe942cd0 is 0x10 bytes (0x2 words)
bin 中的唯一一个 chunk,其 fd 和 bk 都指向自身,而这个 自身,却是 bin 所在位置往前 0x10 字节的地址,即在全局 main_arena 结构体中,.data 段的地址。
下面分别介绍一下各个 bin 中值得一提的特性。
FastBin
fastbinsY 数组中保存着不同长度的单链表头指针,但实际上数组的大小会比链表总数要略大一些,空出来的可能是留着过年。
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4) // 0x50/0xa0
以 32 位程序为例,只用到了 0x10, 0x18, … 0x40 共 7 个 bin,但数组总大小为 11,fastbin 的上限是 0x50 字节;
对于 64 位程序,也是只用到了 0x20, 0x30, …, 0x80 共 7 个 bin,数组大小为 10,理论上最大的 fastbin 可以达到 0xa0 字节;
fastbin 的特性如下:
- 进入 fastbin 的 chunk,其
in-use位为 1,因此不参与相邻块的合并; - 同一个 bin 中所有的 chunk 大小都相等,因此不需要排序;
- 由于 fastbin 是按照最小 chunk 对齐大小增长的,因此从 fastbin 中分配的块必然是 exact fit 的,即申请 chunk 大小与 bin 大小完全一致;
- LIFO,这是为了提升 cache 命中率;
待释放的块 P 进入 fastbin 时,首先获取对应大小 bin 链表头的指针,称为 FP,然后执行以下操作将 P 插入单链表的头部:
P->fd = *FB;
*FB = P;同理,要从 fastbin 取出块时,则直接取出链表头的元素:
P = *FP;
*FP = P->fd;这些指针操作是触发堆漏洞时候构造内存读写原语的重要来源,因此值得重点关注。
Unsorted Bin
- 只有一个,即
bin_at(1) = bins[0]/bins[1] (fd/bk); - 内部的 chunk 可以是任何大小,且如其名字而言,不进行排序;
- 双链表,FIFO;
- 只有一次重新被使用的机会;
- 对于小请求,大部分情况下要求 exact fit,即尺寸一样才会返回;但如果此时bin 中只剩下一个 chunk 且为 last_remainder 且足够大,会对其进行分割,此时是 best fit;
- 分割后多出的部分或者遍历时不满足要求的 chunk 会全部放回到各自的 small/large bin 中;
- 进入 unsorted bin 之前,会先进行前后合并;
待释放的块 P 进入 unsorted bin 时,会插入到 bin 的第一个元素中,如下:
bck = unsorted_chunks(av);
fwd = bck->fd;
P->fd = fwd;
P->bk = bck;
if (!in_smallbin_range(size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p;注意这里用到了本节开头提到的双链表 trick,bck 是双链表的头,这里可以看做是一个 chunk (虽然实际上不是)。 因此,上述双链表插入的时候,并没有像 fastbin 一样直接替换表头,而是插在了表头的后面。
既然是 FIFO,而且在插入时候从表头的 fd 插入,那么取出时自然就优先从链表末尾即 bk 拿出了,取出的相关操作如下:
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
{
bck = victim->bk;
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
}Small Bin
要说特点,Small Bin 可以说是在这些数据结构中最平平无奇的了,包含了一些似乎大家都有的性质,比如:
- 双链表,FIFO;
- 每个 bin 中 chunk 的大小都相同;
- 从中分配的策略属于 best fit;
事实上,small 和 large bin 中的分配策略都属于 best fit,在 malloc 搜索并处理完 unsoted bin 后会对 SB/LB 进行扫描,选出最合适的取出并根据情况进行切割;而 SB/LB 中的 chunk 可能还是刚刚从 UB 中脱出来的。
但也有一些特别的,由于指定 bin 中的 chunk 大小都相同,所以也可以将其中 chunk 的大小称为 bin 的大小。
- Small Bin 本应有
NSMALLBINS = 64个,但bin_at(0)不存在,bin_at(1)是 unsorted bin,因此实际上只有 62 个; - 在 64 位程序中;
- 最小的 small bin 大小为
0x20,最大为0x3f0; - 每个 bin 之间的大小相差
0x10;
- 最小的 small bin 大小为
- 在 32 位程序中:
- 最小的 small bin 大小为
0x10,最大为0x1f8; - 每个 bin 之间的大小相差
0x8;
- 最小的 small bin 大小为
如果没有失忆的话,应该会发现,small bin 和 fast bin 的大小范围有所重叠。但它们的业务范围不同,前者是 unsorted bin 投胎失败后的去处;而后者则是赵家人优待窗口,释放后可以不通过 unsorted bin 直接进入。
更上层的还有天龙人 tcache,后文会详细介绍。
这里先说出链操作,其实和 unsorted bin 类似,都是双链表的删除操作,取的是链表末尾的 chunk:
#define last(b) ((b)->bk)
idx = smallbin_index (nb);
bin = bin_at (av, idx);
if ((victim = last (bin)) != bin) {
bck = victim->bk;
bin->bk = bck;
bck->fd = bin;
}入链相对复杂,在于 regular bin 都只能从 unsorted bin 的残羹冷炙中获取生源。但复杂的是算法,数据操作还是很简单的:
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;bck 是链表头,一个伪 chunk,所以上面的代码本质还是将 victim chunk 插入到链表的头(的下一个位置)。
Large Bin
前文说过,NBINS 一共就 128 个, Small Bin(等等) 占了 64 个,那么剩下来的就是 Large Bin 了。它和其他 bin 相比尽管有一些类似,但更多的是不同。其特性如下:
- 同一个 bin 中块的大小可以不同,不同大小的块需要经过排序,相同大小的采用 FIFO 顺序进出;
- bin 中包含两个双链表;
- 取出时候按照 best fit 的原则获取;
- 不同的 bin 可以分为 6 组,每组的 bin 之间大小间隔公差不同,见下表;
| bin_at | bins | 间隔 | HEX | 备注 |
|---|---|---|---|---|
| 0-63 | 64 | 16 | 0x10 | 62 个 Small Bin, [0x20, 0x400) |
| 64-95 | 32 | 64 | 0x40 | Large Bin, [0x400, 0xc00) |
| 96-111 | 16 | 512 | 0x200 | Large Bin, [0xc00, 0x2c00) |
| 112-119 | 8 | 4096 | 0x1000 | Large Bin, [0x2c00, 0xac00) |
| 120-123 | 4 | 32768 | 0x8000 | Large Bin, [0xac00, 0x2ac00) |
| 124-125 | 2 | 262144 | 0x40000 | Large Bin, [0x2ac00, 0xaac00) |
| 126 | 1 | 其他 | - | Large Bin, [0xaac00, …) |
上面备注的 large bin 每组大小区间可能有点不准确,我是按照间隔大小以及文档中所声明的 bin 个数计算的。但分组本身并不很重要,实际计算以
largebin_index_64宏的结果为准(比如第一组实际上是64~96)。
largebin 中不同 size 的 chunk 使用 fd_nextsize/bk_nextsize 相连,相同 size 的使用 fd/bk 指针相连,例如下图 bin 中有 7 个 chunk:
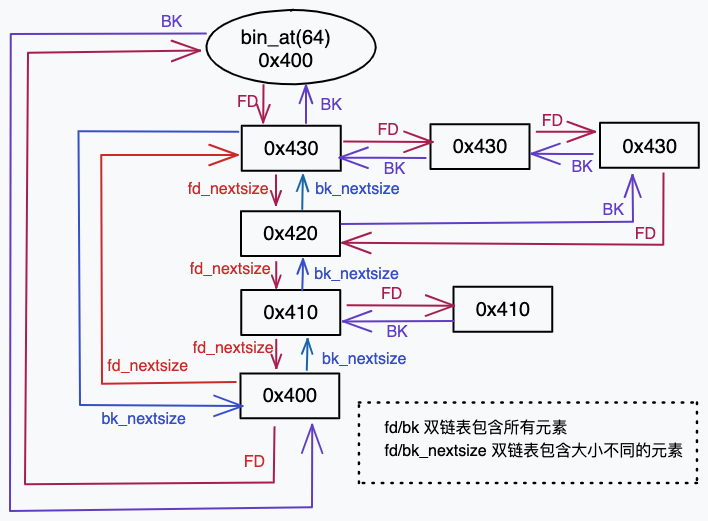
关键点:
- 链表头的
fd指向最大的块;bk指向最小的块; - 相同大小的块中,只有第一个块的
fd_nextsize和bk_nextsize指向下一个大小的块,后续块的 fd_nextsize、bk_nextsize 会置零; fd_nextsize/bk_nextsize属性构成一个循环双链表,从fd第一个元素开始 ,fd_nextsize指向下一个更小的块,最小的块会指向最大的块;注意这个双链表并不包含所有的块;fd/bk属性也构成一个循环双链表,从表头第一个元素开始fd指向下一个 size 小于等于自身 size 的块,串起了所有的块;nextsize双链表不包含表头,因为表头是个伪 chunk,只有 fd 和 bk 属性;
插入 large bin 的流程伪代码如下:
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
if (fwd != bck) {
// 与 bin 中最小的块比较
if (size < chunksize_nomask(bck->bk)) {
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
} else {
// 从 fwd = bin->bk 即最大的块开始搜索
while (size < chunksize_nomask (fwd)) {
fwd = fwd->fd_nextsize;
}
/* 此时 fwd 指向能满足申请 size 的最小块 */
if (size == chunksize_nomask (fwd)) {
// 如果已经存在对应大小的块,插入对应次级链表的第二个位置
fwd = fwd->fd;
} else {
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
}
} else { // bin 为空
victim->fd_nextsize = victim->bk_nextsize = victim;
}
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;代码虽然看起来很复杂,但思路其实很直观,bck 和 fwd 分别表示待插入块所在位置的前后节点,前面一系列操作只是确定其位置,最后执行双链表的插入操作。而对于 fd/bk_nextsize 的操作也和上图中介绍的流程一致,目的还是为了让 chunk 按照大小顺序排好。
删除 large bin 的逻辑也类似:
bin = bin_at (av, idx);
victim = first (bin); // victim = 最大的块
victim = victim->bk_nextsize; // victim = 最小的块
while (((size = chunksize (victim)) < nb)) {
// 从小到大搜索,直至尺寸满足
victim = victim->bk_nextsize;
}
if (victim != last (bin)
&& chunksize_nomask (victim) == chunksize_nomask (victim->fd)) {
// 如果相同尺寸的块不止一个,从第二个开始取,防止修改 nextsize 链表
victim = victim->fd;
}
unlink_chunk (av, victim);unlink_chunk 就是老版本中的 unlink 宏,现在已经升级为了函数,但操作还是一样的,标准双链表删除,其中针对 largebin 的还执行了 nextsize 双链表的删除操作:
unlink_chunk (mstate av, mchunkptr p) {
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
fd->bk = bk;
bk->fd = fd;
/* 确认为 largebin 且 p 在 nextsize 链表中 */
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL) {
if (fd->fd_nextsize == NULL) {
/* 下一个块不在链表中,将其加入 */
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else {
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
} else {
/* 下一个块也在链表中,功成身退 */
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}由前面的逻辑可以推测,如果同样大小的块有不止一个,那么肯定不会删除在 nextsize 双链表中的那个(即第一个)。因此,如果需要从 nextsize 链表中删除,就说明了对应大小的块只有一个。其实这个预设可以简化删除的逻辑,但 unlink 作为通用的函数,不能对传入的 p 做额外预设,因此还是检查了所有情况。
TCache Bin
tcache 也是个缓存,本身就是个数组,比 fastbin 快那么一丢丢,但胜在支持的尺寸多。其主要特性如下:
- 一共有
TCACHE_MAX_BINS = 64个 tcache bin; - 每个 bin 最多只有
TCACHE_FILL_COUNT = 7个 chunk; - bin 之间大小相差
0x10,实际尺寸到索引通过csize2tidx计算; - 最大的 bin 支持的大小为
0x410,实际用户申请的大小要减去头部和对齐;
其实 tcache 从 2.26 加入 glibc 之后,其结构和代码逻辑都发生了很大的变化。早期什么检查都没有,但每一代都会新增一些校验,导致 tcache 已经不是那么好利用了,所以现在基本上都是先将其填满,然后再去利用常规方法进行利用。
算法
这里简单把堆分配和释放的过程记录下来。在遇到一些细节的时候可以去查看相关代码。
malloc
内存的关键分配过程如下:
- 如果 tcache 中有合适的块,直接取出返回;
- 如果 fastbin 中有合适的块,直接返回;
- 如果是小块,则尝试从对应的 smallbin 中取出返回;
- 如果是大块,先
malloc_consolidate; - 循环遍历 unsorted bin:
- 如果请求的是小块,且 bin 中只有一块
last_remainder,且大小满足,则对其进行切割,然后返回; - 不管要不要,先将当前块从 unsorted bin 中删除;
- 如果当前块大小和请求大小完全相等,可直接返回;
- 否则将当前块放到对应的 small、large bin 中;
- 如果请求的是小块,且 bin 中只有一块
- 如果是大块,在 large bin 中搜索最合适的;
- 兜底方案,从
top_chunk中分裂出新的块并返回;
关于 tcache 的横刀夺爱:
- 在第 2 和 第 3 步,相同大小的其他块也会取出放到对应的 tcache bin 中;
- 在 5.3 步,并不直接返回,而是先放到 tcache bin 中然后继续遍历;
- 在 unsorted bin 每次循环的末尾会检查 tcache 有没有拿够,拿够了就放人;
free
接着看内存释放的过程:
- 如果对应的 tcache bin 有空位,直接放进去;
- 如果是 fastbin 的大小,放到对应的 fastbin 中;
- 尝试合并相邻低地址的块,也称为后向合并(backward);
- 如果相邻高地址的块不是 top chunk,则尝试前向合并(forward);
- 否则直接合并然后更新 top chunk,直接返回;
- 将合并后的块放到 unsorted bin 中;
- 合并后的块大小如果大于某个阈值,则触发
malloc_consolidate; - 如果 top chunk 大于
mp.trim_threshold,则执行systrim;
其中 malloc_consolidate 在内存分配的时候也遇到过,主要作用是将 fastbin 中的块都清空并归还系统,能与 top chunk 合并的就合并,不能合并的就插入 unsorted bin 的头部。
不管是 malloc_consolidate 还是 systrim,其目的都是为了减少内存碎片,后者的作用是作为 sysmalloc 的逆操作,通过 brk 系统调用将多余的内存还给系统。
后记
本文算是把 ptmalloc 复习了一遍,重新梳理了其中的亿点细节,并编撰成文以备日后参考。其实很多 CTF 比赛还是能够对现实安全研究带来思路的,去享受,去学习,去分享,也许这才是 CTF 的原本价值吧。
版权声明: 自由转载-非商用-非衍生-保持署名 (CC 4.0 BY-SA)
原文地址: https://evilpan.com/2022/07/17/ptmalloc-notes/
微信订阅: 『有价值炮灰』
– TO BE CONTINUED.