Linux内核代码审计之CVE-2018-9568(WrongZone)
在上一篇文章说到代码审计是漏洞挖掘的一个重要方法,因此本文就尝试用这种方法“挖”出一个知名漏洞。
前言
在很多会议或者文章中,经常能看到大佬分析他们找到的 0day,也有一些原理解释和综述的,但是漏洞挖掘过程,几乎很少有所展现。通常一篇议题的结构就是背景介绍、原理介绍,然后 BOOM 的一下,这里有个漏洞被我发现了,然后是漏洞利用和危害,最后可能秀个视频。对于资深研究人员来说,可以补全自己对某块知识的缺失,但是对于初学者而言,心里一直有个疑问: 没错,这里是漏洞点,但是是怎么想到的?心路历程如何?走了哪些弯路?简而言之,相比于结果,有人更关心的是过程。
漏洞“挖掘”
本文是笔者初学 Linux 内核漏洞时的一篇笔记,遵循(漫谈漏洞挖掘)中提到的学习方法:
- 寻找历史漏洞通告等公开信息;
- 根据漏洞标题自己去尝试审计对应子系统看能否找到漏洞;
- 如果无法找到,再回头看漏洞的细节,思考自己为什么没有能够发现这个问题;
- 不断重复,直到说服自己漏洞挖掘不过是时间问题,而不是能力问题。
这里选取的是 CVE-2018-9568,即 WrongZone 漏洞。当然这个漏洞的漏洞利用过程更为精妙,阿里的王勇、360、百度 XLab 都有详细的利用介绍,不过这不是本文的主题,我们只关注如何通过代码审计找出这个漏洞。
已知的信息如下:
- 该漏洞和 socket 有关
- 该漏洞是 TCP4 和 TCP6 socket 的类型混淆漏洞
根据这些信息尝试自己去找到具体的漏洞点。
入口
一开始真的很难,没有方向,不知道从哪里下手,甚至不知道应该看哪个文件。不过冷静想象就知道了,漏洞要触发还是从用户态进来,所以应该从系统调用开始看。
系统调用的定义为SYSCALL_DEFINEn(name, type, args...),n是参数的个数,根据socket的定义:
int socket(int domain, int type, int protocol);推测系统调用定义为:
SYSCALL_DEFINE3(socket, xxx....)或者直接用正则表达式搜索:
$ egrep "SYSCALL_DEFINE[[:digit:]]" -n -r net/
net/socket.c:1325:SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
net/socket.c:1366:SYSCALL_DEFINE4(socketpair, int, family, int, type, int, protocol,
net/socket.c:1447:SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
net/socket.c:1476:SYSCALL_DEFINE2(listen, int, fd, int, backlog)
net/socket.c:1509:SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
net/socket.c:1583:SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
net/socket.c:1601:SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
...SYSCALL_DEFINEn(socket) 宏展开实际上是定义了一个名为sys_socket的函数。
为什么在 net 目录下搜索?因为 socket 和网络相关,显然是是在网络子系统中。还有其他常见的子系统如下:
- mm: 内存管理子系统
- kernel: 任务调度、进程管理、用户管理
- fs: 各种文件系统的实现
- arch: 处理器架构相关的代码,比如中断向量表,CPU和SOC的定义
- …
这个小技巧有助于快速定位某个子系统的入口。
socket子系统
严格来说socket不是一个子系统,网络才是一个子系统。但我这里还是这样称呼它,将其看作是围绕socket数据结构的一系列操作,比如创建、删除、修改,等等。
socket内核数据结构为:
/**
* struct socket - general BSD socket
* @state: socket state (%SS_CONNECTED, etc)
* @type: socket type (%SOCK_STREAM, etc)
* @flags: socket flags (%SOCK_ASYNC_NOSPACE, etc)
* @ops: protocol specific socket operations
* @file: File back pointer for gc
* @sk: internal networking protocol agnostic socket representation
* @wq: wait queue for several uses
*/
struct socket {
socket_state state;
kmemcheck_bitfield_begin(type);
short type;
kmemcheck_bitfield_end(type);
unsigned long flags;
struct socket_wq __rcu *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};注释还比较清楚,值得注意的是这里说sk为内部网络协议的实现。
socket创建
socket创建流程为:
- sock_create
- sock_alloc()
- new_inode_pseudo
- alloc_inode
- new_inode_pseudo
- pf->create(net, sock, protocol, kern)
- sock_alloc()
没看到有创建socket结构体的地方,只看到初始化了inode,然后通过
sock = SOCKET_I(inode);获得socket指针,alloc_inode实现为:
static struct inode *alloc_inode(struct super_block *sb)
{
struct inode *inode;
if (sb->s_op->alloc_inode)
inode = sb->s_op->alloc_inode(sb);
else
inode = kmem_cache_alloc(inode_cachep, GFP_KERNEL);
// ...
}有时候静态分析不太好确定走的是哪个分支,但根据SOCKET_I宏得知从inode获取sock是根据结构体偏移来的,所以显然inode的分配不单单是从inode_cachep从获取,而是走的上面一个分支,搜索.alloc_inode发现socket.c中果然定义了自己的分配函数sock_alloc_inode,内部通过sock_inode_cachepslub分配socket:
static struct inode *sock_alloc_inode(struct super_block *sb)
{
struct socket_alloc *ei;
struct socket_wq *wq;
ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL);
if (!ei)
return NULL;
wq = kmalloc(sizeof(*wq), GFP_KERNEL);
if (!wq) {
kmem_cache_free(sock_inode_cachep, ei);
return NULL;
}
init_waitqueue_head(&wq->wait);
wq->fasync_list = NULL;
wq->flags = 0;
RCU_INIT_POINTER(ei->socket.wq, wq);
ei->socket.state = SS_UNCONNECTED;
ei->socket.flags = 0;
ei->socket.ops = NULL;
ei->socket.sk = NULL;
ei->socket.file = NULL;
return &ei->vfs_inode;
}sock_alloc是不带参数的,所以对于TCP/UDP/ICMP都是一样的过程,因此实际协议的初始化操作应该是在后面,即pf->create(net, sock, protocol, kern),这里的create也是个虚函数,grep搜索其实现:
$ grep "\.create" -r -n net/
net/ipv4/af_inet.c:1016: .create = inet_create,
net/ipv6/af_inet6.c:613: .create = inet6_create,
...当然正常的查找方法还是根据代码逻辑,通过family(PF_INET)去定位具体的实现。
Tips: 虽然可以从代码中精确查看初始化的过程,但借助经验或者动态调试可以比较快定位到目标关键点。
sock创建
接下来就是具体协议对应的sock创建过程了,先看ipv4:
inet_create(struct net *net, struct socket *sock, int protocol, int kern)- sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern)
sk = sk_prot_alloc(prot, priority | __GFP_ZERO, family)slab = prot->slabsk = kmem_cache_alloc(slab, priority & ~__GFP_ZERO);
- sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern)
对于ipv6也是一样的,因为sk_alloc定义在net/core/sock.c中,后面的实现已经做了抽象,从代码中也可以看到,实际使用的slab为prot->slab。
确定prot的过程也有些tricky,inet_create中prot是answer->prot,什么是answer?这里暂时还不清楚,只知道它是通过查找inetsw数组确定的:
/* The inetsw table contains everything that inet_create needs to
* build a new socket.
*/
static struct list_head inetsw[SOCK_MAX];
// inet_create
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}既然如此,就找找inetsw初始化的地方,如下:
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
rc = proto_register(&raw_prot, 1);
if (rc)
goto out_unregister_udp_proto;
rc = proto_register(&ping_prot, 1);
if (rc)
goto out_unregister_raw_proto;
// ...
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
// ...
/*
* Set the ARP module up
*/
arp_init();
/*
* Set the IP module up
*/
ip_init();
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */
udp_init();
}inet中初始化tcp、udp、raw、icmp等网络协议。
tcp_prot、udp_prot都是全局变量,定义在各自的头文件中。例如tcp4:
// net/ipv4/tcp_ipv4.c
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
// ...
}其中inetsw_array是静态数组,如下:
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
// ..
}ops结构为prot_ops,是对应不同协议的虚函数表。最后调用了tcp_init,如注释所说,初始化tcp的slab缓存。不过只看到了bind slab的创建,socket slab呢?
答案就在proto_register函数中:
int proto_register(struct proto *prot, int alloc_slab)
{
if (alloc_slab) {
prot->slab = kmem_cache_create(prot->name, prot->obj_size, 0,
SLAB_HWCACHE_ALIGN | prot->slab_flags,
NULL);
//...
}
}所以,tcpv4sock所用的slab名称为TCP,大小为 .obj_size = sizeof(struct tcp_sock)。同样的方法去看tcpv6的初始化过程就很快了:
// net/ipv6/tcp_ipv6.c
struct proto tcpv6_prot = {
.name = "TCPv6",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v6_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
// ...
.obj_size = sizeof(struct tcp6_sock),
}tcp6_sock包含了tcp4_sock:
struct tcp6_sock {
struct tcp_sock tcp;
/* ipv6_pinfo has to be the last member of tcp6_sock, see inet6_sk_generic */
struct ipv6_pinfo inet6;
};类型混淆
现在我们知道了各个tcp4、tcp6的创建过程以及其内部的实现,在知道漏洞是类型混淆的前提下,我们怎么去找漏洞呢?一个直接的想法是看内部有没有可以转换类型的代码。在用户态创建tcp4和tcp6 socket的示例如下:
socket(AF_INET, SOCK_STREAM, 0);
socket(AF_INET6, SOCK_STREAM, 0);首先google一通,看有没有可能在INET6和INET4中转换socket,看到一个提问:
里面说到监听在ipv4地址的服务器,可以接受ipv4的连接,虽然这个提问没有回答,但可以顺着这个思路走下去。服务器监听的肯定是INET6的socket,获取客户端的socket为INET4的。服务器接收链接返回socket的函数是accept,查看其在内核中的实现:
/*
* For accept, we attempt to create a new socket, set up the link
* with the client, wake up the client, then return the new
* connected fd. We collect the address of the connector in kernel
* space and move it to user at the very end. This is unclean because
* we open the socket then return an error.
*
* 1003.1g adds the ability to recvmsg() to query connection pending
* status to recvmsg. We need to add that support in a way thats
* clean when we restucture accept also.
*/
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
//...
sock = sockfd_lookup_light(fd, &err, &fput_needed);
//...
newsock = sock_alloc();
//...
newsock->type = sock->type;
newsock->ops = sock->ops;
// ...
err = sock->ops->accept(sock, newsock, sock->file->f_flags, false);
}中间无关的代码我先去掉了,可以更清楚看到accept的逻辑,最终调用的是sock->ops->accept。这个虚函数表刚刚有提到,tcp4是inet_stream_ops,tcp6是inet6_stream_ops。

可以看到虽然部分函数有区别,但是accept都是一样的,对应inet_accept。
int inet_accept(struct socket *sock, struct socket *newsock, int flags,
bool kern)
{
struct sock *sk1 = sock->sk;
int err = -EINVAL;
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern);
// ...
}sk1是原始的sock(即tcp6),sk2是accept返回的sock,这里用到了sk1->sk_prot->accept。回忆一下,sk1->sk_prot,其实是全局变量tcp_prot、tcpv6_prot,分别定义在net/ipv4/tcp_ipv4.c和net/ipv6/tcp_ipv6.c:
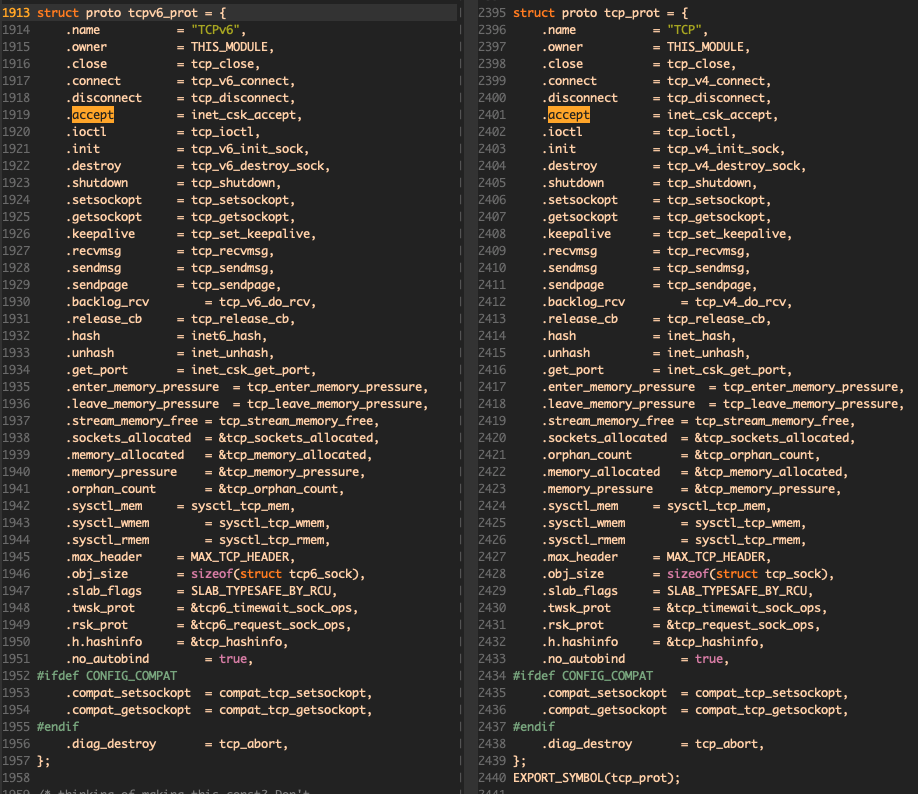
审计inet_csk_accept函数,但并未发现问题,作用就是循环等待队列,不为空时将第一个元素移出队列,元素类型为request_sock。newsk为req->sk。
accept这条路失败后,开始找其他入口,比如ioctl,但是其支持的命令有限,也并未暴露出什么问题。
绝路
根据现有的信息,难以找到潜在的利用点,因此查看了漏洞报告,获取更多信息。不过还没有完全参考报告,而是进一步获得细节:漏洞触发在类型混淆后的释放过程中。
前面我们得知,tcp4和tcp6用的是不同的slab,也就是说,通过这个漏洞,可以让内核将tcp4的sk错误释放到tcp6的slab中(或者相反)。所以,我们自底向上再去审计,研究socket释放的过程。
自底向上
socket是什么时候释放的?直觉认为是close,所以第一时间去看tcp_close函数,其内部实现如下:
- 设置SHUTDOWN_MASK,如果socket在监听,停止监听;
- 从sk_receive_queue中清空接收缓存;
- sk_mem_reclaim,设置好对应的引用计数;
- 对于连接的状态,根据RFC2525,发送FIN或者RST请求,等待结束;
- release_sock/sock_put(sk) 。
其中sock_put的作用是减少引用计数,并在引用计数为零的时候调用sk_free释放socket。释放过程如下:
- sk_free
__sk_free- sk_destruct
__sk_destructsk_prot_free(sk->sk_prot_creator, sk)
static void sk_prot_free(struct proto *prot, struct sock *sk)
{
struct kmem_cache *slab;
struct module *owner;
owner = prot->owner;
slab = prot->slab;
cgroup_sk_free(&sk->sk_cgrp_data);
mem_cgroup_sk_free(sk);
security_sk_free(sk);
if (slab != NULL)
kmem_cache_free(slab, sk);
else
kfree(sk);
module_put(owner);
}注意到这里释放sk是根据sk->sk_prot_creator来决定其释放的slab的,而不是sk->sk_prot,WHY?
IPV6_ADDRFORM
在struct sock的定义中注释有写到:
@sk_prot_creator: sk_prot of original sock creator (see ipv6_setsockopt, IPV6_ADDRFORM for instance)
这给了我们一个新的方向,ipv6_setsockopt/IPV6_ADDRFORM,根据用户文档,这个option的作用是:
IPV6_ADDRFORM
Turn an AF_INET6 socket into a socket of a different address
family. Only AF_INET is currently supported for that. It is
allowed only for IPv6 sockets that are connected and bound to
a v4-mapped-on-v6 address. The argument is a pointer to an
integer containing AF_INET. This is useful to pass v4-mapped
sockets as file descriptors to programs that don't know how to
deal with the IPv6 API.
AF_INET6 -> AF_INET,这就是我们想要的!用户文档中说只允许对已连接的socket使用,并且关联的地址是一个从ipv4地址转成的ipv6地址。注意这里是FORM而不是FROM,估计这里是FORMAT的缩写。
IPV6_ADDRFORM的实现关键部分如下:
if (sk->sk_protocol == IPPROTO_TCP) {
struct inet_connection_sock *icsk = inet_csk(sk);
local_bh_disable();
sock_prot_inuse_add(net, sk->sk_prot, -1);
sock_prot_inuse_add(net, &tcp_prot, 1);
local_bh_enable();
sk->sk_prot = &tcp_prot;
icsk->icsk_af_ops = &ipv4_specific;
sk->sk_socket->ops = &inet_stream_ops;
sk->sk_family = PF_INET;
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
}就在这里,直接改了sk->sk_prot。因此,一个sock的sk_prot是会变化的,所以在释放时才使用sk_prot_creator而不是前者。
那么问题来了,sk_prot_creator是一直不变的吗?
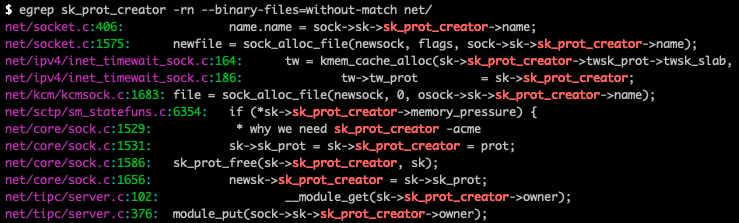
更准确的问法,sk_prot_creator总是正确的吗?如果sk_prot_creator有可能不正确,那这就是类型混淆的源头。在看到sk_clone_lock函数的时候,我基本知道自己是正确的了,因为这个漏洞之前看过,所以记忆中还是有印象的,实际上1656行就是patch修复的代码。
如果我不知道这点的话,我应该是会搜索所有改变sk_prot_creator的地方,看是否能够在用户态主动修改。虽然是有,但并不是直接修改的,而是在sock_copy中:
/*
* Copy all fields from osk to nsk but nsk->sk_refcnt must not change yet,
* even temporarly, because of RCU lookups. sk_node should also be left as is.
* We must not copy fields between sk_dontcopy_begin and sk_dontcopy_end
*/
static void sock_copy(struct sock *nsk, const struct sock *osk)
{
memcpy(nsk, osk, offsetof(struct sock, sk_dontcopy_begin));
memcpy(&nsk->sk_dontcopy_end, &osk->sk_dontcopy_end,
osk->sk_prot->obj_size - offsetof(struct sock, sk_dontcopy_end));
}这是在sk_clone_lock中调用的,搜索这个函数又会发现涉及到net/ipv4/inet_connection_sock.c。anyway,先看copy函数,其实现有问题吗?根据注释的说明,实际上是memcpy前面一段和后面一段,去除中间的。中间部分包括:
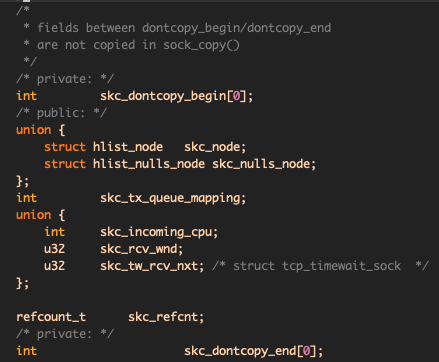
似乎是没有问题的,不复制的部分是一些引用计数和状态。那么也就是说,sk_prot_creator也被复制了,这会导致什么问题吗?在介绍IPV6_ADDRFORM的时候,ipv6的sock变成了ipv4的sock,但只是sk_prot的变化,对于已经分配的对象,还是依然在原本的slub中。如果转换后再复制会怎么样?
struct sock *sk_clone_lock(const struct sock *sk, const gfp_t priority)
{
struct sock *newsk;
bool is_charged = true;
newsk = sk_prot_alloc(sk->sk_prot, priority, sk->sk_family);
if (newsk != NULL) {
struct sk_filter *filter;
sock_copy(newsk, sk);
//...
}
}复制sock首先是用sk->prot去分配,对于转换后的sock是tcp_prot,family是PF_INET,完全看做是tcp4的sock来处理了,但是复制时还是把sk_prot_creator复制了过去,这会导致最后newsk在释放时是当做原来的creator——即tcp6 sock去释放的!所以,我们“找”到了一个类型混淆漏洞!
找到漏洞之后,就看是否能利用了。ipv6_setsockopt比较好触发,就是在用户态调用setsockopt;sk_clone_lock呢?最准确的是动态调试下断点看backtrace,不过还是要先静态分析,前面也提到了,grep大法,发现在inet_connection_sock.c中:
/**
* inet_csk_clone_lock - clone an inet socket, and lock its clone
* @sk: the socket to clone
* @req: request_sock
* @priority: for allocation (%GFP_KERNEL, %GFP_ATOMIC, etc)
*
* Caller must unlock socket even in error path (bh_unlock_sock(newsk))
*/
struct sock *inet_csk_clone_lock(const struct sock *sk,
const struct request_sock *req,
const gfp_t priority)
{
struct sock *newsk = sk_clone_lock(sk, priority);
// ...
}csk,也就是connection socket,是连接状态的socket,以前是从上往下找,现在是从下往下找,调用链路如下:
net/ipv4/inet_connection_sock.c:sk_clone_lock
net/ipv4/tcp_minisocks.c:tcp_create_openreq_child
net/ipv4/tcp_ipv4.c:tcp_v4_syn_recv_sock
net/ipv6/tcp_ipv6.c:tcp_v6_syn_recv_socksyn_recv_sock是 TCP 3次握手成功的回调:
/*
* The three way handshake has completed - we got a valid synack -
* now create the new socket.
*/
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req)接下来静态分析就有点吃力了,我是找了很久,在各个虚函数表之间grep,始终没有找到用户空间的入口,还是直接上gdb方便:
► f 0 c025b1b8 sk_clone_lock
f 1 c02b1278 inet_csk_clone_lock+16
f 2 c02c561c tcp_create_openreq_child+24
f 3 c02c2574 tcp_v4_syn_recv_sock+48
f 4 c02c5c08 tcp_check_req+696
f 5 c02c28a4 tcp_v4_do_rcv+360
f 6 c02c28a4 tcp_v4_do_rcv+360
f 7 c02c4d84 tcp_v4_rcv+1736
f 8 c02a72ac ip_local_deliver_finish+284
f 9 c0265c10 __netif_receive_skb+940
f 10 c0265cd8 process_backlog+112测试各个socket的操作,发现是accept在接收到一个连接时触发的。这也合理解释了为什么要clone socket,因为accept成功返回的就是新链接的clientfd,可见clientfd在内核对应的sock正是克隆出来的newsk。
总结
至此,对该漏洞的正向审计也结束了,这里虽然“找”到了这个漏洞,但其实是有点作弊的,因为在看漏洞通告时无意中瞥到了 clone 之类的单词,所以后面看到 sk_clone_lock 函数的时候就知道十有八九是在这个地方。另外,如果完全不知道漏洞细节,在自顶向下审计的时候我也出现了一个严重的问题,那就是对于 accept 系统调用的分析,当时觉得没有问题,原因是不知道 accept 的返回是依靠内核的三次握手事件触发的返回,而是一味看代码导致忽略了背后的带有生命周期的 TCP 协议栈。
通过自己实际去审计才发现,分析一个漏洞,只需要对子系统有5、6分的了解,很多细节可以针对性跳过;但代码审计却需要对系统有8、9分甚至更多的了解,而且由于是挖掘漏洞,需要至少接触到每个细节。不仅需要从宏观上了解系统架构,还要在微观上评估模块的实现。正所谓——纸上得来终觉浅,绝知此事要躬行。