Linux内核代码审计之CVE-2018-5703
由于第一篇文章是针对网络子系统的,因此这篇也还是找一个网络子系统的漏洞去审计。本文同样是学习 Linux 内核漏洞时的记录,从草稿箱中翻出,稍加修改后在此分享(灌水)一下。
这次选的漏洞是CVE-2018-5703,是syzcaller扫出来的,漏洞报告见: https://groups.google.com/forum/#!msg/syzkaller-bugs/0PBeVnSzfqQ/5eXAlM46BQAJ
已知信息
- Linux master分支,crash的commit为 61233580f1f33c50e159c50e24d80ffd2ba2e06b
- 漏洞出在tcp_v6_syn_recv_sock函数
- 漏洞类型为slab out-of-bound write (实际上是类型混淆)
- 和tls相关
分析
tcp_v6_syn_recv_sock这个函数是定义在虚函数表的syn_recv_sock:
static const struct inet_connection_sock_af_ops ipv6_specific = {
.queue_xmit = inet6_csk_xmit,
.send_check = tcp_v6_send_check,
.rebuild_header = inet6_sk_rebuild_header,
.sk_rx_dst_set = inet6_sk_rx_dst_set,
.conn_request = tcp_v6_conn_request,
.syn_recv_sock = tcp_v6_syn_recv_sock,
.net_header_len = sizeof(struct ipv6hdr),
.net_frag_header_len = sizeof(struct frag_hdr),
.setsockopt = ipv6_setsockopt,
.getsockopt = ipv6_getsockopt,
.addr2sockaddr = inet6_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in6),
.compat_setsockopt = compat_ipv6_setsockopt,
.compat_getsockopt = compat_ipv6_getsockopt,
.mtu_reduced = tcp_v6_mtu_reduced,
};类似的虚函数表在分析上一个漏洞的时候有见过,调用的链路如下:
► f 0 c025b1b8 sk_clone_lock
f 1 c02b1278 inet_csk_clone_lock+16
f 2 c02c561c tcp_create_openreq_child+24
f 3 c02c2574 tcp_v4_syn_recv_sock+48
f 4 c02c5c08 tcp_check_req+696
f 5 c02c28a4 tcp_v4_do_rcv+360
f 6 c02c28a4 tcp_v4_do_rcv+360
f 7 c02c4d84 tcp_v4_rcv+1736
f 8 c02a72ac ip_local_deliver_finish+284
f 9 c0265c10 __netif_receive_skb+940
f 10 c0265cd8 process_backlog+112首先需要理解什么时候会调用到syn_recv_sock,那就需要了解ops虚函数表的作用,connection_sock_af_ops定义在include/net/inet_connection_sock.h:
/*
* Pointers to address related TCP functions
* (i.e. things that depend on the address family)
*/
struct inet_connection_sock_af_ops如注释所说,包含地址(Address Family)相关的TCP函数,connection sock表示带连接的sock,定义如下:
/** inet_connection_sock - INET connection oriented sock
*
* @icsk_accept_queue: FIFO of established children
* @icsk_bind_hash: Bind node
* @icsk_timeout: Timeout
* @icsk_retransmit_timer: Resend (no ack)
* @icsk_rto: Retransmit timeout
* @icsk_pmtu_cookie Last pmtu seen by socket
* @icsk_ca_ops Pluggable congestion control hook
* @icsk_af_ops Operations which are AF_INET{4,6} specific
* @icsk_ulp_ops Pluggable ULP control hook
* @icsk_ulp_data ULP private data
* @icsk_ca_state: Congestion control state
* @icsk_retransmits: Number of unrecovered [RTO] timeouts
* @icsk_pending: Scheduled timer event
* @icsk_backoff: Backoff
* @icsk_syn_retries: Number of allowed SYN (or equivalent) retries
* @icsk_probes_out: unanswered 0 window probes
* @icsk_ext_hdr_len: Network protocol overhead (IP/IPv6 options)
* @icsk_ack: Delayed ACK control data
* @icsk_mtup; MTU probing control data
*/
struct inet_connection_sock;例如,TCP sock就内联了connection sock作为第一个元素,所以tcp_sock指针可以转换成inet_connection_sock指针而没有任何副作用。
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */
// ...
}tcp_v6_syn_recv_sock
既然漏洞出在这个函数,我们就需要先了解这个函数实现的功能。由于其是connection sock的函数,且字段为syn_recv_sock,因此有理由猜测这是TCP协议中接收SYN报文的回调函数。根据TCP协议的状态机,SYN报文会在两种状态下转换,分别是:
- LISTEN状态,Passive Open,接收到SYN,返回SYN+ACK,状态转换成SYN-RECEIVED
- SYN-SENT状态,Active Open,接收到SYN+ACK后,再次发送ACK,完成三次握手,进入ESTABLISHED状态
tcp_v6_syn_recv_sock顾名思义也就是IPv6的tcp链接接收到SYN的处理流程,调用堆栈如下:
►f 0 ffffffff847f4090 tcp_v6_syn_recv_sock
f 1 ffffffff84655422 tcp_get_cookie_sock+258
f 2 ffffffff84847bdd cookie_v6_check+6013
f 3 ffffffff847f9d6d tcp_v6_do_rcv+3661
f 4 ffffffff847f9d6d tcp_v6_do_rcv+3661
f 5 ffffffff847fc73e tcp_v6_rcv+8942
f 6 ffffffff8472c76f ip6_input_finish+879
f 7 ffffffff8472dbe9 ip6_input+233
f 8 ffffffff8472dbe9 ip6_input+233
f 9 ffffffff8472be09 ip6_rcv_finish+425
f 10 ffffffff8472be09 ip6_rcv_finish+425虽然有实现的大致文档,但是关于函数细节的文档通常是没有的,所以,RTFSC!函数原型:
static struct sock *tcp_v6_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
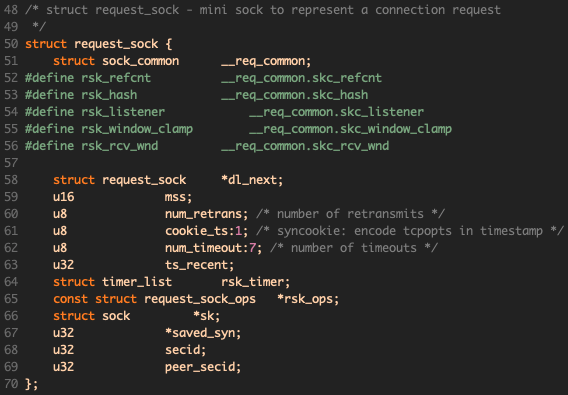
bool *own_req)request_sock包含了一次连接请求所需要的信息:
首先检查协议是不是IP协议,如果是的话表示当前地址是IPv4-to-IPv6的地址,转换成IPv4地址后按照IPv4处理:
if (skb->protocol == htons(ETH_P_IP)) {
/*
* v6 mapped
*/
newsk = tcp_v4_syn_recv_sock(sk, skb, req, dst,
req_unhash, own_req);
// ...
}如果是正常的IPv6协议,则走ipv6的处理流程:
newsk = tcp_create_openreq_child(sk, req, skb);在分析WrongZone漏洞的时候也看到过类似的流程,TCP连接建立会创建新的sock对象newsk,所以用户空间accept在收到新连接时会返回对应newsk的文件描述符。
又类型混淆?
回忆一下WrongZone中的类型混淆漏洞,是由于在运行过程中ipv6 sk的sk_prot被修改了,而新建的sock所使用的slab依赖于sk->sk_prot->slab,从而导致克隆的实际上是修改过类型的sock,与原始sk类型不一致(sk->sk_prot_creator),导致类型混淆。
那么这里是否也是同样的问题呢?其实在翻漏洞报告的时候不小心瞄到了一句话:
tls_init() changes
sk->sk_protfrom IPv6 to IPv4, which leads to this bug.
修改sk->sk_prot从IPv6改为IPv4,效果和IPV6_ADDRFORM一样!后者的实现:
if (sk->sk_protocol == IPPROTO_TCP) {
struct inet_connection_sock *icsk = inet_csk(sk);
local_bh_disable();
sock_prot_inuse_add(net, sk->sk_prot, -1);
sock_prot_inuse_add(net, &tcp_prot, 1);
local_bh_enable();
sk->sk_prot = &tcp_prot; // **BOOM**
icsk->icsk_af_ops = &ipv4_specific;
sk->sk_socket->ops = &inet_stream_ops;
sk->sk_family = PF_INET;
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
}tls_init的实现:
// net/tls/tls_main.c
static inline void update_sk_prot(struct sock *sk, struct tls_context *ctx)
{
sk->sk_prot = &tls_prots[ctx->tx_conf];
}
static int __init tls_register(void)
{
build_protos(tls_prots, &tcp_prot);
tcp_register_ulp(&tcp_tls_ulp_ops);
return 0;
}所以,newsk其实是从TCPv4 Slab中分配的,KASAN的告警触发在下面代码的memcpy处:
newtcp6sk = (struct tcp6_sock *)newsk;
inet_sk(newsk)->pinet6 = &newtcp6sk->inet6;
newtp = tcp_sk(newsk);
newinet = inet_sk(newsk);
newnp = inet6_sk(newsk);
memcpy(newnp, np, sizeof(struct ipv6_pinfo));np为inet6_sk(sk),newnp为inet6_sk(newsk),inet6_sk定义如下:
static inline struct ipv6_pinfo *inet6_sk(const struct sock *__sk)
{
return sk_fullsock(__sk) ? inet_sk(__sk)->pinet6 : NULL;
}tcp6_sock结构:
struct tcp6_sock {
struct tcp_sock tcp;
/* ipv6_pinfo has to be the last member of tcp6_sock, see inet6_sk_generic */
struct ipv6_pinfo inet6;
};发现问题了吗?newsk被强制转换成了tcp6_sock,后者的大小如下:
struct tcp6_sock {
struct tcp_sock tcp; /* 0 2528 */
/* --- cacheline 39 boundary (2496 bytes) was 32 bytes ago --- */
struct ipv6_pinfo inet6; /* 2528 160 */
/* --- cacheline 42 boundary (2688 bytes) --- */
/* size: 2688, cachelines: 42, members: 2 */
};tcp_sock的slab object_size正好是2528,因此强制转换类型之后inet6部分就越界了。事实上KSAN的报错也是如此:
[ 60.682681] The buggy address belongs to the object at ffff880066e4ea80
[ 60.682681] which belongs to the cache TCP of size 2528
[ 60.685803] The buggy address is located 0 bytes to the right of
[ 60.685803] 2528-byte region [ffff880066e4ea80, ffff880066e4f460)
[ 60.689011] The buggy address belongs to the page:
[ 60.690323] page:000000002b421986 count:1 mapcount:0 mapping:000000007a7e240e index:0xffff880066e4fffd compound_mapcount: 0
[ 60.693179] flags: 0x1fffc0000008100(slab|head)
[ 60.694336] raw: 01fffc0000008100 ffff880066e4e000 ffff880066e4fffd 0000000100000003
[ 60.696251] raw: ffff88006a4b9348 ffffea0001ab0ca0 ffff8800690afdc0 0000000000000000
[ 60.698152] page dumped because: kasan: bad access detected
[ 60.699617]
[ 60.700021] Memory state around the buggy address:
[ 60.701230] ffff880066e4f300: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[ 60.703039] ffff880066e4f380: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[ 60.704813] >ffff880066e4f400: 00 00 00 00 00 00 00 00 00 00 00 00 fc fc fc fc
[ 60.706484] ^
[ 60.708036] ffff880066e4f480: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc
[ 60.709746] ffff880066e4f500: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[ 60.711449] ==================================================================
TLS
一个还没解释的问题是,内核如何进入到tls_init? 查看堆栈:
► f 0 ffffffff8468e1a0 tls_init
f 1 ffffffff845724e9 tcp_set_ulp+345
f 2 ffffffff844db4f6 do_tcp_setsockopt.isra+790
f 3 ffffffff844dd3c0 tcp_setsockopt+176
f 4 ffffffff842011b5 sock_common_setsockopt+149
f 5 ffffffff841fc999 sys_setsockopt+393
f 6 ffffffff841fc999 sys_setsockopt+393
f 7 ffffffff8524bb11 entry_SYSCALL_64+113可以看到是通过setsockopt,关于kernel对TLS的支持见文档 https://www.kernel.org/doc/html/latest/networking/tls.html 。简单来说,进入方法就是:
sock = socket(AF_INET, SOCK_STREAM, 0);
setsockopt(sock, SOL_TCP, TCP_ULP, "tls", sizeof("tls"));patch
该漏洞的修复如下:
commit d91c3e17f75f218022140dee18cf515292184a8f
Author: Ilya Lesokhin <ilyal@mellanox.com>
Date: Tue Jan 16 15:31:52 2018 +0200
net/tls: Only attach to sockets in ESTABLISHED state
Calling accept on a TCP socket with a TLS ulp attached results
in two sockets that share the same ulp context.
The ulp context is freed while a socket is destroyed, so
after one of the sockets is released, the second second will
trigger a use after free when it tries to access the ulp context
attached to it.
We restrict the TLS ulp to sockets in ESTABLISHED state
to prevent the scenario above.
Fixes: 3c4d7559159b ("tls: kernel TLS support")
Reported-by: syzbot+904e7cd6c5c741609228@syzkaller.appspotmail.com
Signed-off-by: Ilya Lesokhin <ilyal@mellanox.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
diff --git a/net/tls/tls_main.c b/net/tls/tls_main.c
index e07ee3a..7b7a70e 100644
--- a/net/tls/tls_main.c
+++ b/net/tls/tls_main.c
@@ -454,6 +454,15 @@ static int tls_init(struct sock *sk)
struct tls_context *ctx;
int rc = 0;
+ /* The TLS ulp is currently supported only for TCP sockets
+ * in ESTABLISHED state.
+ * Supporting sockets in LISTEN state will require us
+ * to modify the accept implementation to clone rather then
+ * share the ulp context.
+ */
+ if (sk->sk_state != TCP_ESTABLISHED)
+ return -ENOTSUPP;
+
/* allocate tls context */
ctx = kzalloc(sizeof(*ctx), GFP_KERNEL);
if (!ctx) {
在TLS ULP(upper level protocol)中做了进一步限制,明确指定不支持LISTEN状态的socket设置TLS,虽然是偷懒的做法,但是work。
以史为鉴
说起来这是第二次遇到因为sock的prot类型改变导致的漏洞了,这两个漏洞还是几乎相同时间报出来的。
会不会还存在其他类似的漏洞?简单地grep:
$ egrep "sk->sk_prot = " -nr net/
net/core/sock.c:1530: sk->sk_prot = sk->sk_prot_creator = prot;
net/ipv6/ipv6_sockglue.c:218: sk->sk_prot = &tcp_prot;
net/ipv6/ipv6_sockglue.c:232: sk->sk_prot = prot;
net/tls/tls_main.c:58: sk->sk_prot = &tls_prots[ctx->tx_conf];第二行引起了WrongZone漏洞,第四行引起了本文的漏洞,第一行是创建的时候(sk_alloc),第三行呢?同样是在IPV6_ADDRFORM的处理分支中,与WrongZone漏洞并列,在UDP的分支中。
if (sk->sk_protocol == IPPROTO_TCP) {
struct inet_connection_sock *icsk = inet_csk(sk);
local_bh_disable();
sock_prot_inuse_add(net, sk->sk_prot, -1);
sock_prot_inuse_add(net, &tcp_prot, 1);
local_bh_enable();
sk->sk_prot = &tcp_prot;
icsk->icsk_af_ops = &ipv4_specific;
sk->sk_socket->ops = &inet_stream_ops;
sk->sk_family = PF_INET;
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
} else {
struct proto *prot = &udp_prot;
if (sk->sk_protocol == IPPROTO_UDPLITE)
prot = &udplite_prot;
local_bh_disable();
sock_prot_inuse_add(net, sk->sk_prot, -1);
sock_prot_inuse_add(net, prot, 1);
local_bh_enable();
sk->sk_prot = prot;
sk->sk_socket->ops = &inet_dgram_ops;
sk->sk_family = PF_INET;
}也就是说TCPv6 UDP的socket也会在运行时变化类型(udpv6_prot <--> udp_prot/udplite_prot),这会导致类似的类型混淆问题吗? 这需要跟踪UDP sock的整个生命周期,以及所有可能触达的分支。
当然,根据前面两个漏洞的pattern,范围还可以缩小一些。前面两个漏洞都是发生在sock复制的时候sk_prot_creator没变导致的类型混淆。对于TCP而言,克隆发生在inet_csk_clone_lock,csk表示这是针对connection sock的,内部调用的是sk_clone_lock,搜索所有调用处:
$ egrep "\<sk_clone_lock" -rn --binary-files=without-match net/
net/ipv4/inet_connection_sock.c:781: struct sock *newsk = sk_clone_lock(sk, priority);
net/ipv4/inet_connection_sock.c:852: /* sk_clone_lock locked the socket and set refcnt to 2 */
net/core/sock.c:1638: * sk_clone_lock - clone a socket, and lock its clone
net/core/sock.c:1644:struct sock *sk_clone_lock(const struct sock *sk, const gfp_t priority)
net/core/sock.c:1752:EXPORT_SYMBOL_GPL(sk_clone_lock);只有inet_csk_clone_lock一处调用,所以可以认为UDP协议是不受同类漏洞影响的。
总结
如果不看报告内容的话,即便知道这是一个类型混淆,一开始是找不到这个漏洞点的,根本原因是不知道内核对于 socket 还支持 tls 的功能,而且 tls 还可以改变内核 sock 的 prot 类型。这个例子也可以看出代码审计并非万能(毕竟这是 syzcaller fuzz 出来的),但通过审计形成的理解,我们可以通过简单的 grep 找到更多同类的漏洞,比如上面 UDP6 的潜在类型混淆。
虽然这次没有找到真正的漏洞,但要相信这不过是投入产出比的问题,漏洞只是理解系统的副产品,做之前想好自己真正想要的是什么就可以了。
PS: