URL 解析与鉴权中的陷阱 —— Spring 篇
在上一篇文章中介绍了 Java Web 应用中 URL 解析与鉴权认证中的常见陷阱,但主要针对 Servlet 容器进行分析。前文末尾也提到了,当前 Web 应用多是使用 Spring 全家桶进行开发,其路由匹配方式又与传统 Web 容器有所差异,因此本文就对其进行分析。
DispatcherServlet
新建一个 Spring 项目,通过 start.spring.io 去勾选需要的依赖,然后下载 Maven 或者 Gradle 的工程目录文件,在其中添加自己的业务代码去构建应用。在本节中主要使用 spring-boot-starter-web 为起始工程进行代码编写和分析。
国内用户可以通过 start.springboot.io 镜像进行加速。
默认的项目使用的是 Tomcat 作为 Servlet 容器,因此我们可以利用前一篇文章的知识去快速定位容器中的路由情况。在 org.apache.catalina.mapper.Mapper#internalMapWrapper 中打下断点,查看所有已经注册的 Servlet,发现 exactWrappers、wildcardWrappers、extensionWrappers 等都为空数组,因此路由时会进入到 defaultWrapper,其对应类名为 org.springframework.web.servlet.DispatcherServlet。
我写了个简单的 Controller,如下所示:
@RestController
@RequestMapping("/bind")
public class BinderController {
@GetMapping("str")
String bindString(String p) {
return "Bind: " + p;
}
}在 bindString 中下断点,触发后查看调用栈,截取前半部分如下:
bindString:25, BinderController (com.example.springbootdemo)
invoke0:-1, NativeMethodAccessorImpl (jdk.internal.reflect)
invoke:77, NativeMethodAccessorImpl (jdk.internal.reflect)
invoke:43, DelegatingMethodAccessorImpl (jdk.internal.reflect)
invoke:568, Method (java.lang.reflect)
doInvoke:207, InvocableHandlerMethod (org.springframework.web.method.support)
invokeForRequest:152, InvocableHandlerMethod (org.springframework.web.method.support)
invokeAndHandle:118, ServletInvocableHandlerMethod (org.springframework.web.servlet.mvc.method.annotation)
invokeHandlerMethod:884, RequestMappingHandlerAdapter (org.springframework.web.servlet.mvc.method.annotation)
handleInternal:797, RequestMappingHandlerAdapter (org.springframework.web.servlet.mvc.method.annotation)
handle:87, AbstractHandlerMethodAdapter (org.springframework.web.servlet.mvc.method)
doDispatch:1081, DispatcherServlet (org.springframework.web.servlet)
doService:974, DispatcherServlet (org.springframework.web.servlet)
processRequest:1011, FrameworkServlet (org.springframework.web.servlet)
doGet:903, FrameworkServlet (org.springframework.web.servlet)
service:564, HttpServlet (jakarta.servlet.http)
service:885, FrameworkServlet (org.springframework.web.servlet)
service:658, HttpServlet (jakarta.servlet.http)
// ...
DispatcherServlet 继承自 FrameworkServlet,实现了标准的 Java EE Servlet 接口,因此最初是调用到了 HttpServlet 的 service 方法接口。实际预处理请求以及路由(分发)的方法为 doService,关键代码如下:
protected void doService(HttpServletRequest request, HttpServletResponse response) throws Exception {
logRequest(request);
// ...
if (this.parseRequestPath) {
previousRequestPath = (RequestPath) request.getAttribute(ServletRequestPathUtils.PATH_ATTRIBUTE);
ServletRequestPathUtils.parseAndCache(request);
}
try {
doDispatch(request, response);
}
// ...
}parseAndCache 中对使用 setAttribute 保存请求 URL:
public static RequestPath parseAndCache(HttpServletRequest request) {
RequestPath requestPath = ServletRequestPath.parse(request);
request.setAttribute(PATH_ATTRIBUTE, requestPath);
return requestPath;
}属性的 key 为 PATH_ATTRIBUTE,对应字符串是 org.springframework.web.util.ServletRequestPathUtils.PATH,在后面 doDispatch 进行路由查找的时候使用 getAttribute 获取对应 URL 再进行查找。
在实际调试的时候发现,如果一次 HTTP 请求出错的话,doService 会调用两次,这是因为 Spring 在遇到错误时会将 response 设置为错误返回,然后 Tomcat 会根据配置的自定义错误页面进行再次分发,相应的逻辑在 org.apache.catalina.core.StandardHostValve#invoke:
public void invoke(Request request, Response response) throws IOException, ServletException {
// ...
if (!response.isErrorReportRequired()) {
context.getPipeline().getFirst().invoke(request, response); // 第一次调用
}
response.setSuspended(false);
Throwable t = (Throwable) request.getAttribute(RequestDispatcher.ERROR_EXCEPTION);
// Look for (and render if found) an application level error page
if (response.isErrorReportRequired()) {
// If an error has occurred that prevents further I/O, don't waste time
// producing an error report that will never be read
AtomicBoolean result = new AtomicBoolean(false);
response.getCoyoteResponse().action(ActionCode.IS_IO_ALLOWED, result);
if (result.get()) {
if (t != null) {
throwable(request, response, t);
} else {
status(request, response); // 第二次调用
}
}
}
}错误请求的路由是 /error,因此在第二次请求时会看到 getRequestURI 返回的就是 /error。
doDispatch
DispatcherServlet#doDispatch 的核心简化实现如下:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
processedRequest = checkMultipart(request);
HandlerExecutionChain mappedHandler = getHandler(processedRequest);
if (mappedHandler == null) {
noHandlerFound(processedRequest, response);
return;
}
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
ModelAndView mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
}关键步骤就是三步:
- 查找 handler;
- 查找 HandlerAdapter;
- 调用 handler;
这里介绍下背景知识。在 Spring 中提供了多种定义路由的方法,每一类方法可以使用一个 HandlerMapping 表示,该接口通过 getHandler 获取具体的业务代码对象。
public interface HandlerMapping {
HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception;
}handler 对象封装在 HandlerExecutionChain 类中,其类型是通用的 Object 类。封装类中还包含可选的 HandlerInterceptor 数组,用于给开发者自定义在 handler 之前执行的代码,比如认证或者语言/主题的设置等。
实际调用 handler 即用户定义路由需要通过 HandlerAdapter 实现。这样做的目的主要是为了让 DispatcherServlet 代码中无需知晓 handler 的具体类型,从而具备可拓展的抽象能力。
public interface HandlerAdapter {
boolean supports(Object handler);
ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception;
}handle 接口通过将 handler 转换成实际的类型并进行调用,将结果统一返回为 ModelAndView 类型,然后根据需要进行渲染并将结果写入到 response 完成响应提交的返回。
HandlerMapping
可见,获取对应 HandlerMapping 是路由的重要一步,DispatcherServlet#getHandler 的实现就是从 this.handlerMappings 数组中依次遍历并调用 mapping.getHandler,如果返回不为空则返回对应的 handler 对象。
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
if (this.handlerMappings != null) {
for (HandlerMapping mapping : this.handlerMappings) {
HandlerExecutionChain handler = mapping.getHandler(request);
if (handler != null) {
return handler;
}
}
}
return null;
}handlerMappings 数组中包含多个 HandlerMapping 的实现,根据开发者具体定义的路由确定。这里测试时注册的映射有以下这些:
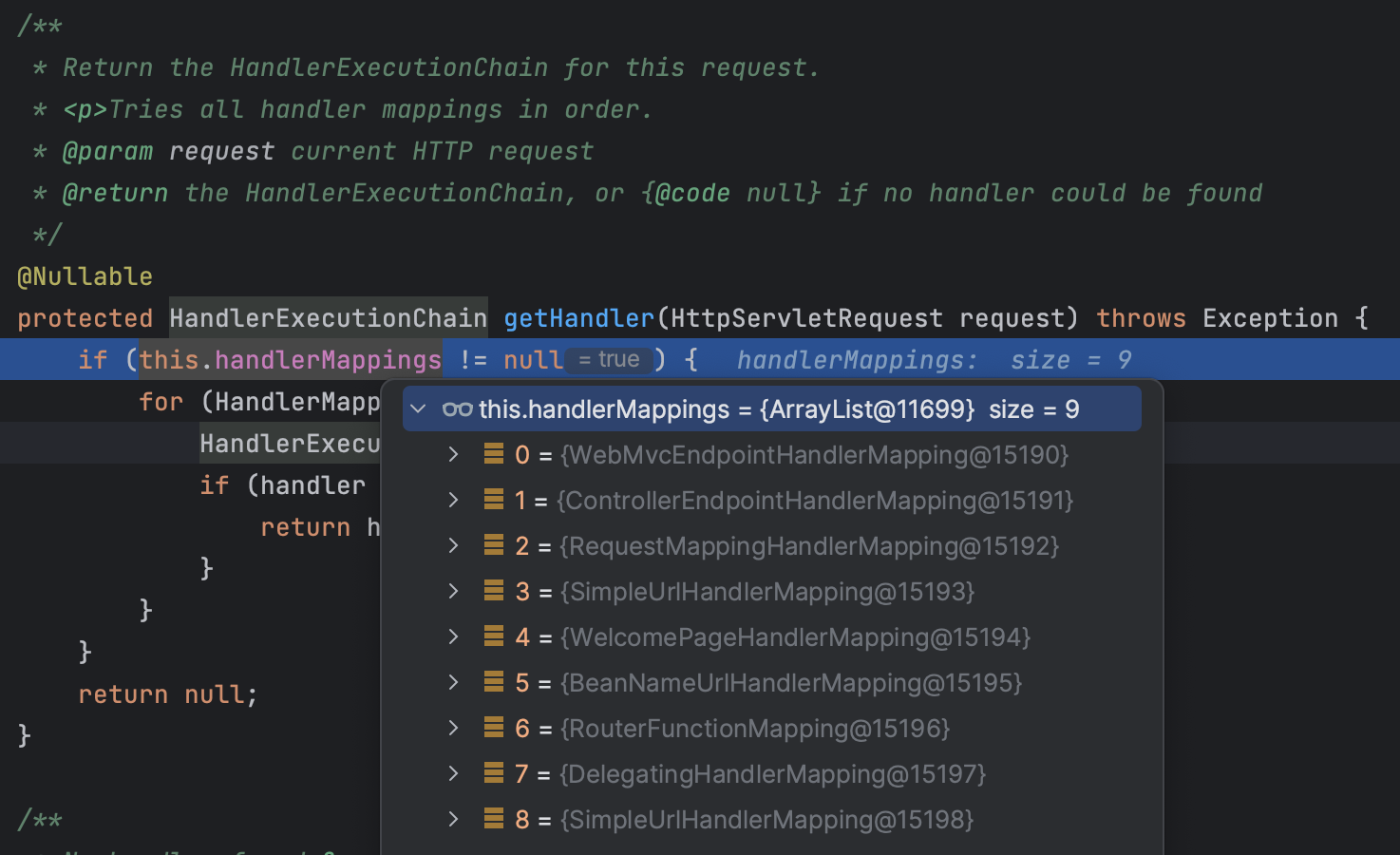
这些映射都是 AbstractHandlerMapping 的子类,在基类中实现了 getHandler 接口,实际返回的 handler 如果是字符串类型则认为是 Bean 的名称,否则认为是实际的 handler:
public final HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
Object handler = getHandlerInternal(request);
if (handler == null) {
handler = getDefaultHandler();
}
if (handler == null) {
return null;
}
// Bean name or resolved handler?
if (handler instanceof String handlerName) {
handler = obtainApplicationContext().getBean(handlerName);
}
HandlerExecutionChain executionChain = getHandlerExecutionChain(handler, request);
return executionChain;
}大致的类结构如下所示,每个版本略有不同,仅作参考:
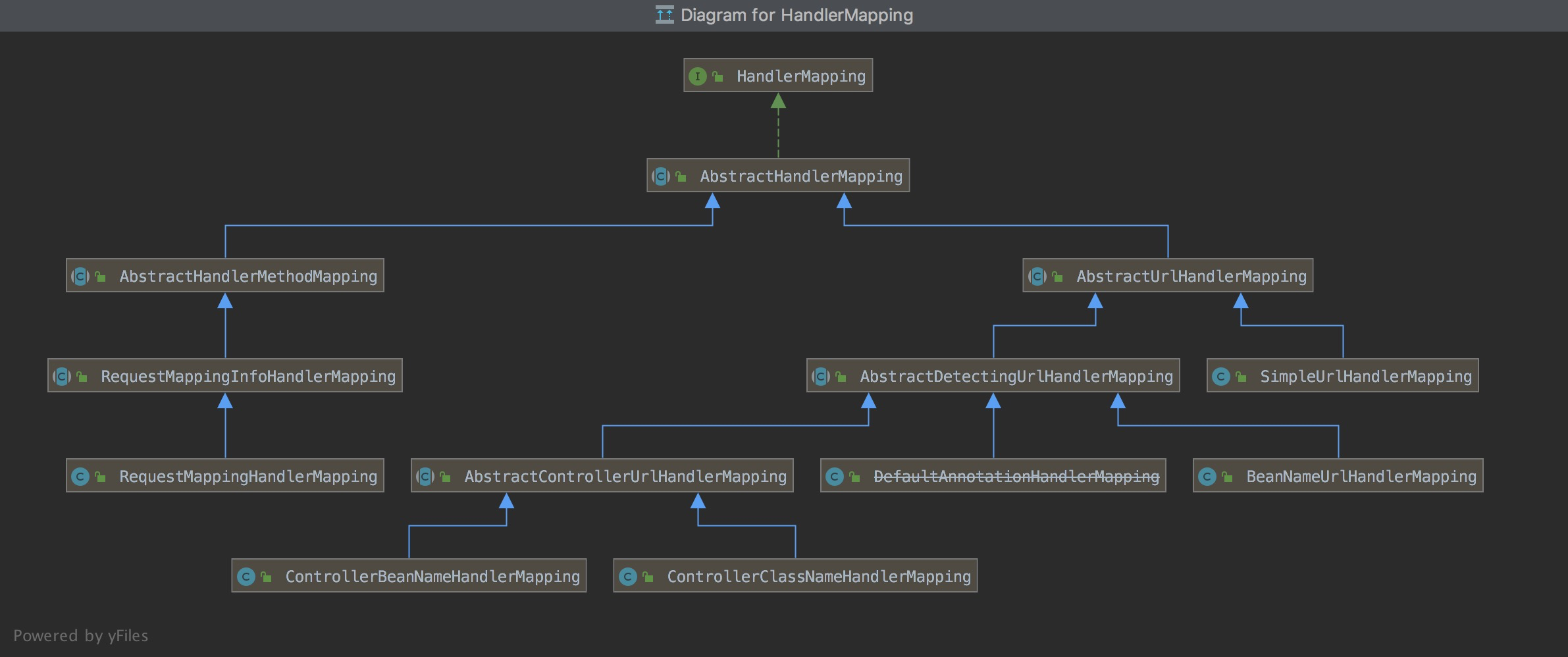
在基类中最终会调用到 lookupHandler:
protected Object lookupHandler(
RequestPath path, String lookupPath, HttpServletRequest request) throws Exception {
Object handler = getDirectMatch(lookupPath, request);
if (handler != null) {
return handler;
}
// Pattern match?
List<PathPattern> matches = null;
for (PathPattern pattern : this.pathPatternHandlerMap.keySet()) {
if (pattern.matches(path.pathWithinApplication())) {
matches = (matches != null ? matches : new ArrayList<>());
matches.add(pattern);
}
}
if (matches == null) {
return null;
}
if (matches.size() > 1) {
matches.sort(PathPattern.SPECIFICITY_COMPARATOR);
if (logger.isTraceEnabled()) {
logger.trace("Matching patterns " + matches);
}
}
PathPattern pattern = matches.get(0);
handler = this.pathPatternHandlerMap.get(pattern);
if (handler instanceof String handlerName) {
handler = obtainApplicationContext().getBean(handlerName);
}
validateHandler(handler, request);
String pathWithinMapping = pattern.extractPathWithinPattern(path.pathWithinApplication()).value();
pathWithinMapping = UrlPathHelper.defaultInstance.removeSemicolonContent(pathWithinMapping);
return buildPathExposingHandler(handler, pattern.getPatternString(), pathWithinMapping, null);
}总结:
- 先使用 getDirectMatch 进行直接匹配,查找
this.handlerMap中的路由; - 后使用模式匹配,依次匹配
this.pathPatternHandlerMap中的路由,具体匹配方法见下节; - 查找完成后对所有匹配进行排序,选出最佳匹配的 handler 进行返回;
由于注册的路由大多数都继承自 AbstractHandlerMapping,因此如果我们想要在运行时查看目标 Spring 应用的所有路由,可以首先断点在 DispatcherServlet#doDispatch,然后遍历其中的 this.handlerMappings,最后读取每个 mapping 中的 handlerMap 和 pathPatternHandlerMap 属性,即可枚举出所有的路由 Pattern。
PathPattern
不同的 HandlerMapping 针对不同的映射类型。主要分为两大类:
- AbstractHandlerMethodMapping: 用于将请求映射到
HandlerMethod; - AbstractUrlHandlerMapping: 用于针对 URL 的映射,比如精确匹配或者模式匹配(PathPattern、AntPathMatcher),多个匹配满足时采用最优(最长)匹配的结果;
一些具体的实现包括但不限于:
- WebMvcEndpointHandlerMapping: 将请求映射到 Spring MVC 控制器方法,用于 Spring Actuator 的端点,如
/actuator/health和/actuator/info等;之所以有这个映射是因为项目中使用了 actuator 模块 (spring-boot-starter-actuator); - ControllerEndpointHandlerMapping: 同上,也是 actuator 中的;
- RequestMappingHandlerMapping: 查找使用
@Controller修饰的类中的@RequestMapping方法,返回方法级别的映射; - SimpleUrlHandlerMapping: 将 URL 映射到 Bean 实例或者 Bean 的名称;
- BeanNameUrlHandlerMapping: 将 URL 映射到以
/开头的 bean,类似于 Struts 将 URL 映射到 action;
我们关心的是 URL 路径到 Handler 的路由或者说匹配规则,因此还需要选择其中几个实现进行深入的跟踪。
以前面定义的 /bind/str 路由为例,其调用路径较深,经过一顿 F7 之后最终可以看到使用 PathPattern.matches 进行匹配,调用栈如下:
matches:42, SeparatorPathElement (org.springframework.web.util.pattern)
matches:216, PathPattern (org.springframework.web.util.pattern)
getMatchingPatterns:203, PathPatternsRequestCondition (org.springframework.web.servlet.mvc.condition)
getMatchingCondition:195, PathPatternsRequestCondition (org.springframework.web.servlet.mvc.condition)
getMatchingCondition:397, RequestMappingInfo (org.springframework.web.servlet.mvc.method)
getMatchingMapping:110, RequestMappingInfoHandlerMapping (org.springframework.web.servlet.mvc.method)
getMatchingMapping:68, RequestMappingInfoHandlerMapping (org.springframework.web.servlet.mvc.method)
addMatchingMappings:447, AbstractHandlerMethodMapping (org.springframework.web.servlet.handler)
lookupHandlerMethod:407, AbstractHandlerMethodMapping (org.springframework.web.servlet.handler)
getHandlerInternal:382, AbstractHandlerMethodMapping (org.springframework.web.servlet.handler)
getHandlerInternal:126, RequestMappingInfoHandlerMapping (org.springframework.web.servlet.mvc.method)
getHandlerInternal:68, RequestMappingInfoHandlerMapping (org.springframework.web.servlet.mvc.method)
getHandler:505, AbstractHandlerMapping (org.springframework.web.servlet.handler)
getHandler:1275, DispatcherServlet (org.springframework.web.servlet)
PathPattern 是以斜杠 / 为间隔的路径模式,遵循以下规则:
?匹配单个字符;*匹配单个路径段(path segment)之间的零个或者多个字符;**匹配零个或者多个路径段,直至路径结尾;{spring}: 匹配一个路径段并且捕捉该段保存为变量 “spring”;{spring:[a-z]+}: 同上,但要求路径段满足正则表达式[a-z]+;{*spring}: 类似于**,但将匹配的路径段保存为变量 “spring”;
其规则类似于与我们之前介绍 Shiro 时用的 Ant 风格路径匹配(Ant Style Path Matcher)。
Ant 指的是最早在 Apache Ant 使用的匹配方法,不同于正则表达式,主要是为了实现 JavaEE Servlet 的路径匹配规则。
PathPattern 内部包含一个 PathElement 格式的 head 属性,以双链表的形式保存了所有路径段和分隔符,head 指向路径的开头即 SeparatorPathElement Separator(/)。
public boolean matches(PathContainer pathContainer) {
if (this.head == null) {
return !hasLength(pathContainer) ||
(this.matchOptionalTrailingSeparator && pathContainerIsJustSeparator(pathContainer));
}
else if (!hasLength(pathContainer)) {
if (this.head instanceof WildcardTheRestPathElement || this.head instanceof CaptureTheRestPathElement) {
pathContainer = EMPTY_PATH; // Will allow CaptureTheRest to bind the variable to empty
}
else {
return false;
}
}
MatchingContext matchingContext = new MatchingContext(pathContainer, false);
return this.head.matches(0, matchingContext);
}head.matches 不断匹配下一级路径或者分隔符(this.next),并调用其 matches 方法进行匹配。head 即 SeparatorPathElement 的实现如下:
public boolean matches(int pathIndex, MatchingContext matchingContext) {
if (pathIndex < matchingContext.pathLength && matchingContext.isSeparator(pathIndex)) {
if (isNoMorePattern()) {
if (matchingContext.determineRemainingPath) {
matchingContext.remainingPathIndex = pathIndex + 1;
return true;
}
else {
return (pathIndex + 1 == matchingContext.pathLength);
}
}
else {
pathIndex++;
return (this.next != null && this.next.matches(pathIndex, matchingContext));
}
}
return false;
}其他的 PathElement 接口实现包括:
- org.springframework.web.util.pattern.SeparatorPathElement
- org.springframework.web.util.pattern.WildcardPathElement
- org.springframework.web.util.pattern.SingleCharWildcardedPathElement
- org.springframework.web.util.pattern.WildcardTheRestPathElement
- org.springframework.web.util.pattern.CaptureVariablePathElement
- org.springframework.web.util.pattern.CaptureTheRestPathElement
- org.springframework.web.util.pattern.LiteralPathElement
- org.springframework.web.util.pattern.RegexPathElement
比如 /foo 就包含一个 SeparatorPathElement 和一个 LiteralPathElement,后者的 value 为 foo。LiteralPathElement 的实现如下:
public boolean matches(int pathIndex, MatchingContext matchingContext) {
if (pathIndex >= matchingContext.pathLength) {
// no more path left to match this element
return false;
}
Element element = matchingContext.pathElements.get(pathIndex);
if (!(element instanceof PathSegment pathSegment)) {
return false;
}
String value = pathSegment.valueToMatch();
if (value.length() != this.len) {
// Not enough data to match this path element
return false;
}
if (this.caseSensitive) {
if (!this.text.equals(value)) {
return false;
}
}
pathIndex++;
// ...
return (this.next != null && this.next.matches(pathIndex, matchingContext));
}其他的 PathElement 都有不同实现,这里就不一一介绍了。
PathContainer 也是类似的数据结构,其中 elements 数组中包含了所有解析的路径段和分隔符,类型为 Element;对于路径段使用子接口 PathSegment 表示,拥有返回路径参数以及解码路径值的能力。
interface PathSegment extends Element {
/**
* Return the path segment value, decoded and sanitized, for path matching.
*/
String valueToMatch();
char[] valueToMatchAsChars();
/**
* Path parameters associated with this path segment.
* @return an unmodifiable map containing the parameters
*/
MultiValueMap<String, String> parameters();
}从中我们可以看出路径匹配的算法:
- 应用启动时解析所有的 Controller 等各种路由映射,将其以 PathPattern 的格式存储在不同 HandlerMapping 中;
- 收到请求时,DispatcherServlet 会将请求路径解析为
PathContainer,将路径中的元素(Path Element)保存到列表中,元素包含路径分隔符和每一级路径的内容;其中路径内容使用 PathSegment 表示,其valueToMatch返回的是不带路径参数且 URL 解码后的内容,精确匹配时会使用 String.equals 进行对比; - 实际比较时,PathContainer 会被封装成 MatchingContext,包括当前比对的位置等信息,方便使用
.next遍历链表时保存比较的上下文信息; - 路径比对会从表头开始,依次调用
next.matches,直至最后一级,此时next为 null;
就 RequestMappingHandlerMapping 而言,我们能够针对路径做的变异如下,假设原始路径为 /api/flag:
/api/%66%6C%61%67: 基于 valueToMatch 返回 URL 解码后的的 segment 值;/api;a=b/flag: 基于 valueToMatch 返回不包含路径参数的值;
注意 /api/./flag 或者 /api/../api/flag 这种请求时无法路由到目标 Handler 的,因为匹配时会将 dot-segment 当成一般的路径去进行精确匹配,因此只能路由到 @GetMapping("/./flag) 对应的 Handler 上。
参考资料:
ResourceHttpRequestHandler
对于常规 Servlet 容器,在所有定义的路由都无法匹配时,会尝试从磁盘文件或者 jar 中的资源文件进行匹配,即所说的 DefaultServlet。Spring MVC 也有类似的行为,当前面所有的 HadlerMapping 都找不到匹配时,会尝试查找对应的资源文件,负责处理这部分操作的是最后一个 SimpleUrlHandlerMapping,其 beanName 为 resourceHandlerMapping。
其中的 pathPatternHandlerMap 默认包含两个 PathPattern,分别是:
/webjars/**->ResourceHttpRequestHandler [classpath [META-INF/resources/webjars/]]/**->ResourceHttpRequestHandler [classpath [META-INF/resources/], classpath [resources/], classpath [static/], classpath [public/], ServletContext [/]]
/** 是一个 PathElement,称为 WildcardTheRestPathElement,用于匹配所有 / 开头的路径。
最后调用 handler 的是 HttpRequestHandlerAdapter,实现比较简单,就是直接调用 handler.handleRequest:
public ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
((HttpRequestHandler) handler).handleRequest(request, response);
return null;
}handleRequest
读取资源文件的 handleRequest 实现如下:
public void handleRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// For very general mappings (e.g. "/") we need to check 404 first
Resource resource = getResource(request);
if (resource == null) {
logger.debug("Resource not found");
response.sendError(HttpServletResponse.SC_NOT_FOUND);
return;
}
// Supported methods and required session
checkRequest(request);
// Header phase
// Apply cache settings, if any
// Check the media type for the resource
// Content phase
if (request.getHeader(HttpHeaders.RANGE) == null) {
this.resourceHttpMessageConverter.write(resource, mediaType, outputMessage);
} else {
ServletServerHttpRequest inputMessage = new ServletServerHttpRequest(request);
List<HttpRange> httpRanges = inputMessage.getHeaders().getRange();
response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);
this.resourceRegionHttpMessageConverter.write(
HttpRange.toResourceRegions(httpRanges, resource), mediaType, outputMessage);
}
}请求只支持 GET 和 OPTIONS 方法,并且支持 HTTP 缓存,对于未修改的资源可以返回 304;此外还有个值得注意的点是这里还支持了 HTTP Range 头,即从指定偏移开始读取文件。
资源分为两种,一种是 classpath resource,即 Jar 包中的文件,另一种是 ServletContext resource,即 Web 目录中的磁盘文件。是否能够定位到对应文件的关键是 getResource 是否能成功返回对于资源:
protected Resource getResource(HttpServletRequest request) throws IOException {
String path = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE);
if (path == null) {
throw new IllegalStateException("Required request attribute '" +
HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE + "' is not set");
}
path = processPath(path);
if (!StringUtils.hasText(path) || isInvalidPath(path)) {
return null;
}
if (isInvalidEncodedPath(path)) {
return null;
}
Assert.state(this.resolverChain != null, "ResourceResolverChain not initialized.");
Assert.state(this.transformerChain != null, "ResourceTransformerChain not initialized.");
Resource resource = this.resolverChain.resolveResource(request, path, getLocations());
if (resource != null) {
resource = this.transformerChain.transform(request, resource);
}
return resource;
}首先关注局部变量 path,该值是之前保存到属性中的。回顾之前 HandlerMapping 一节中 lookupHandler 的代码末尾。pathWithinMapping,这个参数会在 buildPathExposingHandler 中使用,最终会创建一个拦截器 PathExposingHandlerInterceptor,而这个拦截器会在 DispatcherServlet 中调用 handler 前调用,即 mappedHandler.applyPreHandle()。该拦截器会使用 request 的属性保存该 URL,且这个 URL 就是这里寻址资源时用到的 path 值:
String pathWithinMapping = pattern.extractPathWithinPattern(path.pathWithinApplication()).value();
pathWithinMapping = UrlPathHelper.defaultInstance.removeSemicolonContent(pathWithinMapping);
return buildPathExposingHandler(handler, pattern.getPatternString(), pathWithinMapping, null);buildPathExposingHandler 中设置属性:
request.setAttribute(PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE, pathWithinMapping);因此,这里的 path 会经过一部分预处理。
预处理
PathPattern#extractPathWithinPattern 中的处理方法还是从 path element 的维度去处理,如果其中有连续的分隔符会进行合并,随后会返回从第一个非分隔符的元素一直到最后一个非分隔符的元素,因此路径 /foo//bar/ 处理后会变成 foo/bar。
removeSemicolonContent 则是删除 URL 中的路径参数。
仅从这个预处理的代码片段来看,路径 /foo/;/bar 处理后依旧会保留连续的分隔符形成 foo//bar,当然具体影响还要看后续的处理代码。
processPath
在获得部分处理的路径后,会继续经过 processPath 过滤,代码如下:
protected String processPath(String path) {
path = StringUtils.replace(path, "\\", "/");
path = cleanDuplicateSlashes(path);
return cleanLeadingSlash(path);
}
private String cleanLeadingSlash(String path) {
boolean slash = false;
for (int i = 0; i < path.length(); i++) {
if (path.charAt(i) == '/') {
slash = true;
}
else if (path.charAt(i) > ' ' && path.charAt(i) != 127) {
if (i == 0 || (i == 1 && slash)) {
return path;
}
return (slash ? "/" + path.substring(i) : path.substring(i));
}
}
return (slash ? "/" : "");
}- 将
\替换为了/; - 删除重复的
/,比如//; - 删除路径前部的
/,准确来说是所有/和控制符(00-1F, 7F)的组合;
注意 cleanLeadingSlash 的实现,会从第一个字符开始查找,直到找到第一个大于 \x20 且不等于 \x7F 的字符,返回此后的子字符串,根据期间是否出现过 / 来判断结果是否要在前方添加 /。
isInvalidPath
processPath 之后会判断路径是否为空且是否为合法的路径,判断方法为:
protected boolean isInvalidPath(String path) {
if (path.contains("WEB-INF") || path.contains("META-INF")) {
return true;
}
if (path.contains(":/")) {
String relativePath = (path.charAt(0) == '/' ? path.substring(1) : path);
if (ResourceUtils.isUrl(relativePath) || relativePath.startsWith("url:")) {
return true;
}
}
if (path.contains("..") && StringUtils.cleanPath(path).contains("../")) {
return true;
}
return false;
}其中对请求资源的路径做了几个限制:
- 不能包含
WEB-INF或者META-INF; - 不能是 URL;
- 对于包含
..的路径,使用cleanPath不能再包含../;
ResourceUtils.isUrl 的实现的伪代码如下:
public static boolean isUrl(String resourceLocation) {
if (resourceLocation.startsWith("classpath:")) {
return true;
}
try {
new URL(location);
return true;
} catch (MalformedURLException ex) {
return false;
}
}除了以 classpath: 开头的路径,其他都依赖于 java.net.URL 构造函数中的处理,即如果能成功调用 URL 的构造函数就认为是一个 URL。根据官方文档,URL 构造函数抛出异常的条件是:
if no protocol is specified, or an unknown protocol is found, or spec is null.
感觉这里还是有点操作空间的,比如从源码中对比一下 Spring 支持而 URL 不支持的协议。
StringUtils.cleanPath 的作用主要是将路径进行归一化,不过考虑到 path 可能包含特殊的协议头,要考虑的情况就变得相对复杂了:
public static String cleanPath(String path) {
String normalizedPath = replace(path, WINDOWS_FOLDER_SEPARATOR, FOLDER_SEPARATOR);
String pathToUse = normalizedPath;
// 去除协议部分
int prefixIndex = pathToUse.indexOf(':');
String prefix = "";
if (prefixIndex != -1) {
prefix = pathToUse.substring(0, prefixIndex + 1);
if (prefix.contains(FOLDER_SEPARATOR)) {
prefix = "";
}
else {
pathToUse = pathToUse.substring(prefixIndex + 1);
}
}
if (pathToUse.startsWith(FOLDER_SEPARATOR)) {
prefix = prefix + FOLDER_SEPARATOR;
pathToUse = pathToUse.substring(1);
}
// 处理路径树
String[] pathArray = delimitedListToStringArray(pathToUse, FOLDER_SEPARATOR);
Deque<String> pathElements = new ArrayDeque<>(pathArray.length);
int tops = 0;
for (int i = pathArray.length - 1; i >= 0; i--) {
String element = pathArray[i];
if (".".equals(element)) {
// Points to current directory - drop it.
} else if ("..".equals(element)) {
// Registering top path found.
tops++;
} else {
if (tops > 0) {
// Merging path element with element corresponding to top path.
tops--;
}
else {
// Normal path element found.
pathElements.addFirst(element);
}
}
}
// All path elements stayed the same - shortcut
if (pathArray.length == pathElements.size()) {
return normalizedPath;
}
// Remaining top paths need to be retained.
for (int i = 0; i < tops; i++) {
pathElements.addFirst(TOP_PATH);
}
// If nothing else left, at least explicitly point to current path.
if (pathElements.size() == 1 && pathElements.getLast().isEmpty() && !prefix.endsWith(FOLDER_SEPARATOR)) {
pathElements.addFirst(CURRENT_PATH);
}
final String joined = collectionToDelimitedString(pathElements, FOLDER_SEPARATOR);
// avoid string concatenation with empty prefix
return prefix.isEmpty() ? joined : prefix + joined;
}cleanPath 中使用的算法是将路径以 / 分隔,并将列表从后往前进行处理,最后将列表重新组合成新的路径。值得注意的是该方法只是将路径中的 . 去除以及将路径中间的 .. 移动到前方,比如 foo/../../bar 会变成 ../bar,因此该方法的注释中也说了不能讲其作为安全校验来防止路径穿越。这也是为什么要对 cleanPath 之后的路径再次检查是否存在 ../ 的原因。这样过滤的好处是可以找出归一化后以 ../ 开头的路径,即目录穿越到 web 应用 context-root 之外的路径。
回顾 isInvalidPath 的实现,此时 path 虽然经过了一定的处理,但现在还是包含 URL 编码字符的,因此猜测这里并不是唯一的安全校验,否则可以被比较容易地绕过。不过从这个判断的实现上来看,我们可以学习到 Spring 对于资源请求的一些设计,比如支持 URL、classpath: 和 url: 格式的资源,以及 WEB-INF 路径中的文件被认为是敏感信息等。
isInvalidEncodedPath
接着看下一个判断,isInvalidEncodedPath,根据其实现正好验证了我们上节的猜想,即 path 如果包含 URL 编码,需要对解码后的路径再次进行安全判断:
private boolean isInvalidEncodedPath(String path) {
if (path.contains("%")) {
try {
// Use URLDecoder (vs UriUtils) to preserve potentially decoded UTF-8 chars
String decodedPath = URLDecoder.decode(path, StandardCharsets.UTF_8);
if (isInvalidPath(decodedPath)) {
return true;
}
decodedPath = processPath(decodedPath);
if (isInvalidPath(decodedPath)) {
return true;
}
}
catch (IllegalArgumentException ex) {
// May not be possible to decode...
}
}
return false;
}URL 解码后的路径进行了两次判断,第一次是针对解码后的原始 URL,第二次是 processPath 之后的 URL,判断和前面一样都是通过 isInvalidPath。
Resource
在经过一系列前置判断后,最后开始使用 resolveResource 查找资源。基于 getLocations() 返回的 classpath resource 或者 context resource 分别进行查找:
// org.springframework.web.servlet.resource.PathResourceResolver#getResource()
for (Resource location : locations) {
String pathToUse = encodeOrDecodeIfNecessary(resourcePath, request, location);
Resource resource = getResource(pathToUse, location);
if (resource != null) {
return resource;
}
}encodeOrDecodeIfNecessary 对请求的路径进行了 URL 解码。当然主要取决于对应请求的 HandlerMapper 配置,对于大部分映射而言只要请求使用 PathContainer 封装就需要进行解码;在一些特殊的 HandlerMapper 中可能会已经对请求进行解码,因此这里反而会需要进行编码。
getResource 使用 Resource.createRelative 获取指定资源文件,并且在获取到后还使用 checkResource 进行了额外的防御性检查:
protected Resource getResource(String resourcePath, Resource location) throws IOException {
Resource resource = location.createRelative(resourcePath);
if (resource.isReadable()) {
if (checkResource(resource, location)) {
return resource;
}
else if (logger.isWarnEnabled()) {
Resource[] allowed = getAllowedLocations();
logger.warn(LogFormatUtils.formatValue(
"Resource path \"" + resourcePath + "\" was successfully resolved " +
"but resource \"" + resource.getURL() + "\" is neither under " +
"the current location \"" + location.getURL() + "\" nor under any of " +
"the allowed locations " + (allowed != null ? Arrays.asList(allowed) : "[]"), -1, true));
}
}
return null;
}Resource 是 Spring 中一个真的资源的抽象接口,具有多种实现,包括前面介绍过的,比如:
- ClassPathResource: 使用 Class.getResource 或者 ClassLoader.getResource 接口去读取对应文件;
- ServletContextResource: 使用
ServletContext.getResource或者ServletContext.getRealPath读取 web 应用目录下相对路径的文件; - FileSystemResource: 使用 java.io.File 接口读取磁盘文件;
- …
每种资源的实现各不相同,但总的来说 createRelative 大都是通过 StringUtils.applyRelativePath(this.path, relativePath) 构造新的 Resource。
至于 checkResource 的实现这里就不展开了,除非你已经绕过了 getResource 之前对路径的重重校验。这里主要是进行防御性的检查,判断新的资源是否在原始资源目录之下,根据资源类型的不同可能会调用 getURL 或者 getPath 作为资源的路径,并使用 String.startsWith 对整理后的路径进行比较。
Bypass Tricks
通过上面对 Spring MVC 路由代码的分析可以看出,对于大多数 HandlerMethodMapping,Spring 使用 PathPattern 去进行路径匹配,类似于 Ant 风格的最优匹配方式,因此对指定路由的变异相比于 Tomcat 等 Web 容器而言会少很多;但是对于资源文件的路由则可以使用更多变种。
假设存在资源文件 resources/static/secret.txt,对应的路由是 /secret.txt,可以使用下面的变体:
/secret.txt/: 预处理时候会变成secret.txt删除前方以及末尾的分隔符;/;/secret.txt: 预处理时候删除连续的分隔符,和//的差别是处理阶段不同;/secret.txt;a=b: 预处理时候会删除路径参数;\secret.txt: 基于 processPath 中将\替换成/的变异;//secret.txt: 基于 cleanDuplicateSlashes 的变异,因此前面遗留的连续分隔符不会影响;/ / // secret.txt: 基于 cleanLeadingSlash 的变异;/secret.%74%78%74: 寻找文件前会通过 encodeOrDecodeIfNecessary 进行 URL 解码;/foo/.././/secret.txt: createRelative 中会组合路径,并将其当做最终路径;
这些路径变异方式可以组合进行使用,从而根据需要构造出更加复杂的变异。当然值得注意的是其中某些变异可能会在 Web 容器就被拦截,比如 Tomcat 在碰到路径中包含(未编码的)空格时会直接返回 400 错误。
Spring Security
前面详细分析了 Spring MVC 的路由实现,在实际的 Spring 应用中通常配套使用 Spring-Security 作为认证和鉴权方案,因此本节将二者结合起来看,以加深对鉴权逻辑的理解。另外也会分析一些历史上出现过的 Spring Security 鉴权绕过漏洞,结合实际案例进行分析。
如无特别说明,本节使用的安全配置代码如下:
@Configuration
@EnableWebSecurity
public class SecurityConfig {
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http.csrf().disable()
.authorizeHttpRequests((requests) -> requests
.requestMatchers("/secret.txt").hasRole("USER")
.requestMatchers("/api/flag").hasRole("USER")
.requestMatchers("/**").permitAll()
)
.formLogin((form) -> form
.loginPage("/login").permitAll()
)
.logout(LogoutConfigurer::permitAll);
return http.build();
}
}本文使用的版本是
spring-security-web6.0.3
通用防御
首先构造一个简单的变异 /api/flag;xxx 进行请求后发现结果直接返回 400,在 DispatcherServlet 中直接看到请求的是 /error 界面。因此猜测在 Spring Security 引入的某个 Filter 中拦截了请求。
调试方式还是在 org.apache.catalina.core.ApplicationFilterChain#internalDoFilter 中遍历每个 filter 时进行断点,最终发现在 org.springframework.web.filter.DelegatingFilterProxy#doFilter 中触发了 response.setError,从而跳出循环并查找自定义错误页面进行输出。
在 org.springframework.security.web.FilterChainProxy#doFilter 中内部抛出了异常并被捕捉,异常类的详细信息如下:
org.springframework.security.web.firewall.RequestRejectedException: The request was rejected because the URL contained a potentially malicious String ";"
at org.springframework.security.web.firewall.StrictHttpFirewall.rejectedBlocklistedUrls(StrictHttpFirewall.java:535)
at org.springframework.security.web.firewall.StrictHttpFirewall.getFirewalledRequest(StrictHttpFirewall.java:505)
at org.springframework.security.web.FilterChainProxy.doFilterInternal(FilterChainProxy.java:211)
at org.springframework.security.web.FilterChainProxy.doFilter(FilterChainProxy.java:191)
at org.springframework.web.filter.DelegatingFilterProxy.invokeDelegate(DelegatingFilterProxy.java:352)
at org.springframework.web.filter.DelegatingFilterProxy.doFilter(DelegatingFilterProxy.java:268)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:174)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:149)
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:116)
即核心在于 StrictHttpFirewall 的拦截。下面是调用方的代码:
// org.springframework.security.web.FilterChainProxy
private void doFilterInternal(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
FirewalledRequest firewallRequest = this.firewall.getFirewalledRequest((HttpServletRequest) request);
HttpServletResponse firewallResponse = this.firewall.getFirewalledResponse((HttpServletResponse) response);
List<Filter> filters = getFilters(firewallRequest);
if (filters == null || filters.size() == 0) {
if (logger.isTraceEnabled()) {
logger.trace(LogMessage.of(() -> "No security for " + requestLine(firewallRequest)));
}
firewallRequest.reset();
this.filterChainDecorator.decorate(chain).doFilter(firewallRequest, firewallResponse);
return;
}
if (logger.isDebugEnabled()) {
logger.debug(LogMessage.of(() -> "Securing " + requestLine(firewallRequest)));
}
FilterChain reset = (req, res) -> {
if (logger.isDebugEnabled()) {
logger.debug(LogMessage.of(() -> "Secured " + requestLine(firewallRequest)));
}
// Deactivate path stripping as we exit the security filter chain
firewallRequest.reset();
chain.doFilter(req, res);
};
this.filterChainDecorator.decorate(reset, filters).doFilter(firewallRequest, firewallResponse);
}在请求 firewall.getFirewalledRequest 时抛出了异常:
public FirewalledRequest getFirewalledRequest(HttpServletRequest request) throws RequestRejectedException {
rejectForbiddenHttpMethod(request);
rejectedBlocklistedUrls(request);
rejectedUntrustedHosts(request);
if (!isNormalized(request)) {
throw new RequestRejectedException("The request was rejected because the URL was not normalized.");
}
rejectNonPrintableAsciiCharactersInFieldName(request.getRequestURI(), "requestURI");
return new StrictFirewalledRequest(request);
}对于请求的拦截包括:
- rejectForbiddenHttpMethod: 拦截非法的请求方法,默认允许的方法为 HEAD, DELETE, POST, GET, OPTIONS, PATCH, PUT 这 7 个;
- rejectedBlocklistedUrls: 拦截 URL 中的特殊字符,
- encodedUrlBlocklist:
//,\x00,%2F2F,%00,%25,\n,\r,%5C,%3B,%0A,%2E,%2F,%0D,;,\; - decodedUrlBlocklist:
//,\x00,%2F2F,%00,%,\u2028,\u2029\n,\r,%5C,%3B,%0A,%2F,%0D,;,\;
- encodedUrlBlocklist:
- rejectedUntrustedHosts: 拦截不可信的请求域名 (request.getServerName);
- isNormalized: 拦截包含
./,/../,/.字符的路径; - rejectNonPrintableAsciiCharactersInFieldName: 拦截
getRequestURI中包含不可打印字符的请求,即小于\x20或者大于\x7e的字符;
在 2 中两个 Blocklist 略有不同,二者都检查了 getContextPath 的值,但前者检查的是 getRequestURI,而后者检查的是 getPathInfo 的值;这里列举的字符我删除了一些大小写的变体,具体分类如下:
public StrictHttpFirewall() {
urlBlocklistsAddAll(FORBIDDEN_SEMICOLON);
urlBlocklistsAddAll(FORBIDDEN_FORWARDSLASH);
urlBlocklistsAddAll(FORBIDDEN_DOUBLE_FORWARDSLASH);
urlBlocklistsAddAll(FORBIDDEN_BACKSLASH);
urlBlocklistsAddAll(FORBIDDEN_NULL);
urlBlocklistsAddAll(FORBIDDEN_LF);
urlBlocklistsAddAll(FORBIDDEN_CR);
this.encodedUrlBlocklist.add(ENCODED_PERCENT);
this.encodedUrlBlocklist.addAll(FORBIDDEN_ENCODED_PERIOD);
this.decodedUrlBlocklist.add(PERCENT);
this.decodedUrlBlocklist.addAll(FORBIDDEN_LINE_SEPARATOR);
this.decodedUrlBlocklist.addAll(FORBIDDEN_PARAGRAPH_SEPARATOR);
}在 4 中检查的路径包括 getRequestURI、getContextPath、getServletPath 以及 getPathInfo;
可见在当前版本的默认配置下,Spring Security 拦截了很多 URL 的变体,从而在后续鉴权检查的时候避免了许多潜在的绕过。其中大部分选项都可以配置关闭,比如使用 setAllowSemicolon 来允许分号(路径参数),详见 StrictHttpFirewall 中的接口。一个重要的例外是 isNormalized 的检查无法关闭,官方文档中的解释是:
There is no way to disable this as it is considered extremely risky to disable this constraint. A few options to allow this behavior is to normalize the request prior to the firewall or using DefaultHttpFirewall instead. Please keep in mind that normalizing the request is fragile and why requests are rejected rather than normalized.
另外其实针对可打印字符的拦截也是无法关闭的,只不过这里的检查并没有考虑对这些字符 URL 编码的情况。
AuthorizationFilter
在本节开头的 SecurityConfig 中放了一个类型为 SecurityFilterChain 的 bean,并设置了以下规则:
.requestMatchers("/api/flag").hasRole("USER")直接请求 /api/flag 会返回 302 跳转到配置的登录地址。想要分析这背后的原理可以和之前一样继续在 FilterChainProxy 中跟踪返回的每个 filter:
List<Filter> filters = getFilters(firewallRequest);这里直接说结论,最终检查上述规则的 Filter 是 AuthorizationFilter,使用 AuthorizationManager#check 来对路径进行权限检查。
// org.springframework.security.web.access.intercept.AuthorizationFilter#doFilter
AuthorizationDecision decision = this.authorizationManager.check(this::getAuthentication, request);
this.eventPublisher.publishAuthorizationEvent(this::getAuthentication, request, decision);
if (decision != null && !decision.isGranted()) {
throw new AccessDeniedException("Access Denied");
}
chain.doFilter(request, response);AuthorizationDecision 只是 bool 的简单封装,保存 isGrant 即认证的结果是否通过。RequestMatcherDelegatingAuthorizationManager#check 的关键实现如下:
public AuthorizationDecision check(Supplier<Authentication> authentication, HttpServletRequest request) {
this.logger.trace(LogMessage.format("Authorizing %s", request));
for (RequestMatcherEntry<AuthorizationManager<RequestAuthorizationContext>> mapping : this.mappings) {
RequestMatcher matcher = mapping.getRequestMatcher();
MatchResult matchResult = matcher.matcher(request);
if (matchResult.isMatch()) {
AuthorizationManager<RequestAuthorizationContext> manager = mapping.getEntry();
this.logger.trace(LogMessage.format("Checking authorization on %s using %s", request, manager));
return manager.check(authentication,
new RequestAuthorizationContext(request, matchResult.getVariables()));
}
}
this.logger.trace(LogMessage.of(() -> "Denying request since did not find matching RequestMatcher"));
return DENY;
}this.mappings 保存了 RequestMatcherEntry 类型的列表,请求是否命中规则的判断使用 RequestMatcher#matcher 进行匹配,命中匹配后再使用 AuthorizationManager#check 判断权限是否满足,这里我们显然主要关注前者。
RequestMatcher 接口是 Spring Security 中用于匹配请求的关键接口,具体实现有 antMatchers、regexMatchers 等,这里 /api/flag 对应的是 MvcRequestMatcher,实现如下:
public MatchResult matcher(HttpServletRequest request) {
if (notMatchMethodOrServletPath(request)) {
return MatchResult.notMatch();
}
MatchableHandlerMapping mapping = getMapping(request);
if (mapping == null) {
return this.defaultMatcher.matcher(request);
}
RequestMatchResult result = mapping.match(request, this.pattern);
return (result != null) ? MatchResult.match(result.extractUriTemplateVariables()) : MatchResult.notMatch();
}其中实际使用了 org.springframework.web.servlet.handler.MatchableHandlerMapping 去进行路径匹配,这个类正是 Spring MVC 中使用的,该映射类通过内省的方式获取,因此避免了检查和路由不一致的问题,从而防止各种路径变异导致的绕过。当然只能说顶层设计是这样的,但具体实现可能依然有些阴暗的角落,这个可以从近期的一些案例中看到。
历史案例
在 Spring {Boot,Data,Security} 历史漏洞研究 一文中提及到相关的漏洞,这里再深入分析一下。早期 Spring Security 的配置支持 antMatchers, mvcMatchers, 以及 regexMatchers 等多种路径匹配方式,但这些匹配方法多少还是和 Spring MVC 中的路由匹配规则是有差异的。
比如在 SEC-2534 漏洞中,Spring Security 的 antMatchers("/link") 配置与 Spring MVC 的 @RequestMapping("/link") 配置可以被 /link.html 绕过。
在 CVE-2016-5007 中,可以在路径中加入空格来绕过 Spring Security 的判断(早期 Spring Framework 使用 AntPathMatcher 可配置忽略空格且默认开启)。
在 CVE-2022-22975/CVE-2022-22978 中,基于正则表达式的 RegexRequestMatcher 在使用点号 . 比如 .* 时可以被换行符绕过。这是一个正则表达式常见的陷阱,一般使用 Pattern.DOTALL 来指明点号匹配包括换行符的所有字符。
这些漏洞的核心在于,Spring 框架对于路径匹配的规则提供了相比于 Spring Security 更加丰富的配置方法,而用户可以轻易地在二者之间开启不同的配置,导致二者不匹配产生鉴权绕过。针对这类问题,当时开发组提出了一种与 Spring MVC 对齐的匹配方法,即 MvcRequestMatcher。该类使用了 Spring MVC 中的 HandlerMappingIntrospector 来匹配路径和提取变量,从而根治了鉴权和路由不一致的问题。
在新版 Spring Security 的官方文档中也提到,建议开发者使用新的 requestMatcher 接口,并将历史接口的废弃提上日程:
In Spring Security 5.8, the antMatchers, mvcMatchers, and regexMatchers methods were deprecated in favor of new requestMatchers methods. https://docs.spring.io/spring-security/reference/5.8/migration/servlet/config.html
除此之外还有一些鸡肋漏洞,比如 Spring Security 与 WebFlux 的匹配,或者应用在使用 Spring 的基础上还使用了其他 Servlet,又或者是一些特殊配置下的鉴权绕过,这里就不展开介绍了。
参考资料:
- SEC-2534: Security mapping of “/something” and @RequestMapping("/something") can be by passed using /something.html
- CVE-2016-5007 Spring Security / MVC Path Matching Inconsistency
- CVE-2022-22978: Authorization Bypass in RegexRequestMatcher
- issue#3964: Add MvcRequestMatcher
- org.springframework.security.web.servlet.util.matcher.MvcRequestMatcher
Shiro
在 前文 中介绍了 Shiro 针对 Java EE 应用的基本配置以及 URL 路径的过滤和匹配代码实现。实际上在 Shiro 中 Spring 也是一等公民,有单独的配置选项,见: Integrating Apache Shiro into Spring-Boot Applications。
针对 Spring MVC 的路径鉴权匹配实现和针对一般 Java Web 应用的实现大同小异,回顾前文的代码片段:
// org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain
final String requestURI = getPathWithinApplication(request);
final String requestURINoTrailingSlash = removeTrailingSlash(requestURI);
for (String pathPattern : filterChainManager.getChainNames()) {
if (pathMatches(pathPattern, requestURI)) {
return filterChainManager.proxy(originalChain, pathPattern);
} else {
// 针对 Spring Web 的处理
pathPattern = removeTrailingSlash(pathPattern);
if (pathMatches(pathPattern, requestURINoTrailingSlash)) {
return filterChainManager.proxy(originalChain, pathPattern);
}
}
}其中针对 Spring Web 会进行额外处理,即删除 pathPattern 中末尾的分隔符再进行一次比对。值得注意的是 getPathWithinApplication 中使用的路径并不是 getRequestURI 而是 getServletPath + getPathInfo,这几个常见路径的官方介绍如下:
- getRequestURI: 原始 HTTP 请求路径部分在请求参数(即
?)之前部分的内容,这是最原始的数据,包含原样的用户输入; - getContextPath: 对应 Context 的路径,即 Web 容器挂载对应应用的前缀;
- getServletPath: 调用对应 Servlet 时的(相对)路径,不包含 Context 部分,且删除了路径参数;
- getPathInfo: 额外设置的路径信息,默认为 null;
不管如何,Shiro 会尝试使用“干净”的路径去匹配鉴权规则,这在 Spring MVC 项目中与 Spring Security 比起来就多了很多潜在的鉴权路由不匹配风险。基本上 Spring Security 出现过的问题很可能也会在 Shiro 中出现。
比如,Spring Security 中 CVE-2016-5007,通过在路径添加空格的方式绕过鉴权,在 Shiro 中就有 CVE-2020-17510 和 CVE-2020-17523 等针对 AntPathMatcher 的绕过方式;
又比如,Spring Security 中 regexMatcher 正则表达式 DOTALL 问题导致的 CVE-2022-22978,在 Shiro 中也有几乎一样的 CVE-2022-32532,针对 RegExPatternMatcher 的绕过方式;
关于更多 Shiro 的历史漏洞介绍和分析,可以参考已有的优秀文章,比如 Shiro 历史漏洞分析。
总结
相比于传统的 JavaEE Web 应用,Spring 基于全匹配的 DispatcherServlet 实现了一套应用层的路由方案,并且在依赖注入的加持下使得业务开发和配置变得更加方便。这一套路由方案屏蔽了底层 Servlet 容器的解析差异,但同时也引入了 Spring 特有的解析陷阱。在不断的更新过程中,Spring Security 逐渐与 MVC 对齐,使用相同的路径匹配方法,从而避免鉴权和路由不一致的问题,但是 Shiro 就没那么幸运了,作为 “外拨秧” 缺乏官方的支持,只能寻求更为通用的解决方案,但未来这类不匹配的问题可能还是依旧会出现。
通过最近两篇文章针对 URL 路径鉴权的分析,对解析路径时会遇到的陷阱也算有了基本了解。虽然文章只介绍了 Java Web 生态的 URL 鉴权实现,但对于其他应用也是类似的。核心在于 TOCTOU 即判断和最终使用的变量不一致问题。这一类问题不仅出现在 Web 中,在二进制世界经常也是导致条件竞争、UAF 之类漏洞的元凶,值得我们在漏洞挖掘时重点关注。
参考链接
版权声明: 自由转载-非商用-非衍生-保持署名 (CC 4.0 BY-SA)
原文地址: https://evilpan.com/2023/08/19/url-gotchas-spring/
微信订阅: 『有价值炮灰』
– TO BE CONTINUED.